печать конвертов и уведомлений онлайн на принтере. Новая программа
Добрый день! Сервис «Почтум» приветствует вас! Для вас уже создан личный кабинет. И вы уже в него вошли. Никаких дополнительных действий для регистрации не требуется. Продолжайте работу. Все введенные адреса сохраняются в вашем личном кабинете. Рекомендуем лишь привязать адрес электронной почты к вашему кабинету. Электронный адрес может пригодиться для воостановления доступа.
Мы рады, что можем помочь вам в выполнении такой рутинной работы, как заполнение и печать почтовых конвертов и уведомлений. Сервис предназначен для автоматизации вашей работы. После того, как вы распечатаете 10 конвертов вы поймете, что у вас стало уходить существенно меньше времени на подготовку и отправку писем.
Как тратить минимум времени на работу с почтой?
Наиболее удобный формат конвертов — С5. С самоклеющейся полосой, без
разлиновки.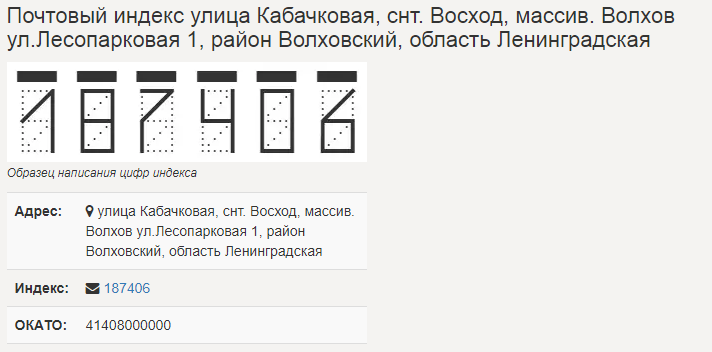
Для юридических лиц Почта России предлагает марки по безналичному расчету. Вы будете покупать их один-два раза в год. Что это дает? Конверты с наклеенными марками вы можете отдать сотруднику Почты России без очереди, или положить их в почтовый ящик. Не нужно стоять в очередях. Как это сделать смотрите здесь.
Пакетная печать позволяет заполнять и печатать любое количество конвертов за один раз. Для этого необходимо выбрать нужных получателей и положить пачку конвертов в принтер.
Подготовьте список получателей в формате EXCEL. Перейдите на страницу загрузки адресов. Сервис проверит правильность заполнения адресов и наименований. Доступна функция автоматического извлечения индекса из адреса.
Возможности программы
Все введенные
вами адреса сохраняются на сервере. Резервное копирование —
ежедневное. Доступ к личному кабинету с любого компьютера,
подключенного к Интернету.
Резервное копирование —
ежедневное. Доступ к личному кабинету с любого компьютера,
подключенного к Интернету.
Адрес отправителя, адрес получателя, индексы заполняются автоматически. Теперь не нужно обводить индекс ручкой. Весь процесс занимает несколько секунд.
Вы можете печатать конверты всех допустимых форматов: C6, DL, C5, C4, B4. На обычном принтере можно распечатать C6, DL, C5. Для печати в формате C4 и B4 необходим принтер, позволяющий печатать листы размером А3. В такие конверты листы А4 умещаются целиком.
Для отправки заказных писем неободимо заполнять уведомления о вручении. В сервисе «Почтум» этот процесс полностью автоматизирован. На листе А4 можно распечатать 4 уведомления о вручении Ф-119. Сначала печатается лицевая сторона, затем — оборотная.
В левом верхнем
углу над адресом отправителя можно расположить логотип вашей компании.
Вы можете загрузить свой логотип или выбрать один из предложенных.
Пакетная печать позволяет за один раз сформировать и выдать на печать до 500 конвертов или уведомлений. Необходимо лишь выбрать нужных получателей. Вы можете объединять получателей в списки и сохранять их. Это могут быть, например, «Арендаторы», «Поставщики» и т.п.
python — Распечатать индексы совпадающих элементов списка
Я не могу понять, почему это печатает [0, 2, 3, 3]. Мне нужно напечатать индекс каждого элемента в lst1, который равен соответствующему элементу в lst2
[0, 2, 3]. Я новичок в python, поэтому я не должен понимать порядок, в котором циклы for перебирают список или что-то в этом роде.def same_values(lst1, lst2):
final = []
for num in lst1:
if lst2[lst1.index(num)] == num:
final.append(lst1.index(num))
return final
print(same_values([5, 1, -10, 3, 3], [5, 10, -10, 3, 5]))
-2
Derek Cook 7 Сен 2020 в 17:55
3 ответа
Лучший ответ
Ошибка возникает из-за того, что код lst1.
Безопаснее использовать другой подход:
def same_values(lst1, lst2):
final = []
for i in range(len(lst1)):
if lst1[i] == lst2[i]:
final.append(i)
return final
print(same_values([5, 1, -10, 3, 3], [5, 10, -10, 3, 5]))
Выход:
[0, 2, 3]
3
Daniel Labbe 7 Сен 2020 в 15:06
lst1.index(3)
3 оба раза, потому что это первое вхождение 3 в lst1.Вместо этого вы можете использовать zip для итерации по списки параллельно и enumerate для доступа к индексу .
def same_values(lst1, lst2):
final = []
for i, (v1, v2) in enumerate(zip(lst1, lst2)):
if v1 == v2:
final. append(i)
return final
print(same_values([5, 1, -10, 3, 3], [5, 10, -10, 3, 5])) # -> [0, 2, 3]
append(i)
return final
print(same_values([5, 1, -10, 3, 3], [5, 10, -10, 3, 5])) # -> [0, 2, 3]
Здесь бит for i, (v1, v2) in ... использует вложенную итеративную распаковку.
Кроме того, вы можете упростить это до понимания, хотя это немного шумно:
def same_values(lst1, lst2):
return [i for i, (v1, v2) in enumerate(zip(lst1, lst2)) if v1 == v2]
1
wjandrea 7 Сен 2020 в 15:29
5, -10, 3, 3 совпадают, потому что вы каждый раз просматриваете весь второй список
Примечание: вы можете получить индекс и элемент, используя enumerate
for i, num in enumerate(lst1):
Если вы хотите сравнить «соответствующие индексы», получите доступ к обоим спискам и сравните, а не «найдите индекс соответствующего элемента» с помощью
Также ознакомьтесь с функцией zip()
0
OneCricketeer 7 Сен 2020 в 15:06
Печать фотографий
НОВИНКА! УСЛУГА ЗАКАЗА ПЕЧАТИ ФОТОГРАФИЙ С НАШЕГО САЙТА!
ЗАКАЖИ ФОТОГРАФИИ со своего компьютера или смартфона не выходя из дома! Это удобно!
МОМЕНТАЛЬНАЯ ПЕЧАТЬ НА ФОТОКИОСКАХ KODAK
|
10×15 |
20р. |
|
15×20 |
40р. |
ЦИФРОВАЯ ПЕЧАТЬ НА ФОТОЛАБОРАТОРИЯХ NORITSU 3101, 3301 И 3000
|
10×15 |
14р. |
|
15×20 |
28р. |
|
15×21 |
28р. |
|
20×30 |
45р. |
|
20×10 |
28р. |
|
20×25 |
45р. |
|
30×30 |
130р. |
|
30×40 |
140р. |
|
30×45 |
150р. |
|
Панорама 13×30 |
40р.
|
|
Панорама 15×36 |
50р. |
|
Панорама 20×45 |
100р. |
|
Индекс-принт 10×15 |
20р. |
|
Индекс-принт 15×20 |
30р. |
|
Индекс-принт 20×30 |
80р. |
ДОПОЛНИТЕЛЬНЫЕ УСЛУГИ
| Проявка плёнки | 150р. |
| Кадрирование | 10р. |
| Сканирование плёнки (1000×1500, выборочно) | 10р. |
| Сканирование плёнки (1000×1500, все подряд) | 6р. |
| Сканирование плёнки (2000×3000) |
20р.
|
| Сканирование плёнки (3000×4500) | 40р. |
| Сканирование (одиночные кадры) | 12р. |
К ПЕЧАТИ ПРИНИМАЮТСЯ:
- фотоплёнки негативные, чёрно-белые, слайдовые 35мм и 120мм, APS
- длиной не менее 4 кадров.
- цифровые носители: дискеты, CD-диски,DVD-диски, карты памяти,
- мобильные телефоны, поддерживающие Bluetooth-соединение.
ТРЕБОВАНИЯ К ФАЙЛАМ ДЛЯ ПЕЧАТИ:
- цвет RGB; разрешение 300-320 dpi;
- формат файлов jpg, bmp, tiff, psd;
- имена латинскими буквами без пробелов.
ПАРАМЕТРЫ ФАЙЛОВ ДЛЯ ПЕЧАТИ
|
ФОРМАТ |
РАЗМЕР (мм) |
РАЗРЕШЕНИЕ (пиксели, 320dpi – NORITSU3101/3000) |
РАЗРЕШЕНИЕ (пиксели, 300dpi – NORITSU 3301) |
|
10 x 15 |
102 x 152 |
1285 x 1915 |
1205 x 1795 |
|
15 x 20 |
152 x 203 |
1915 x 2557 |
1795 x 2398 |
|
15 x 21 |
152 x 216 |
1915 x 2721 |
1795 x 2551 |
|
15 x 23 |
152 x 228 |
1915 x 2872 |
1795 x 2693 |
|
20 x 30 |
203 x 305 |
2557 x 3843 |
2398 x 3602 |
|
21 x 30 |
210 x 305 |
2646 x 3843 |
2480 x 3602 |
|
30 x 40 |
305 x 407 |
3843 x 5128 |
3602 x 4807 |
|
30 x 45 |
305 x 457 |
3843 x 5757 |
3602 x 5398 |
- По фотографиям, напечатанным в режиме «real-size», претензии не принимаются.

Возврат к списку
Печать фотографий | FOQUS
Мы можем напечатать Ваши фотографии вручную, непосредственно с пленки, а можем – цифровым способом напечатать отсканированные фотографии на фото-принтере. А если вам нужна накатка ваших фотографий на пенокартон, такая услуга также есть в нашей лаборатории.
Цифровая печать фотографий:Печать фотографий на профессиональных цифровых минилабораториях Noritsu. Перед заказом на печать фотографий с фотопленки рекомендуем заказать услугу по сканированию фотографий для получения максимально хорошего качества выбранных изображений.
Печать фотографий на глянцевой/матовой бумаге, цена за кадр:
| Размер | Цена |
| 10 x 15 | 16 р. |
| 13 x 18 | 21 р. |
| 15 x 20 | 32 р. |
| 20 x 30 | 75 р. |
| 30 x 40 | 128 р. |
| 30 x 45 | 144 р. |
Средние сроки готовности – 1-2 будних дня.
Широкоформатная цифровая печать фотографий:Фотографии печатаются на профессиональных лабораториях Durst Theta.
Широкоформатная цифровая печать на глянцевой/матовой фотобумаге, цена за кадр:
| Размер | Цена |
| 40 x 50 | 440 р. |
| 40 x 60 | 530 р. |
| 50 x 60 | 660 р. |
| 50 x 70 | 770 р. |
| 60 x 90 | 1190 р. |
| 70 x 100 | 1540 р. |
| 76 x 400 | 6690 р. |
Средние сроки готовности – 1-3 будних дня.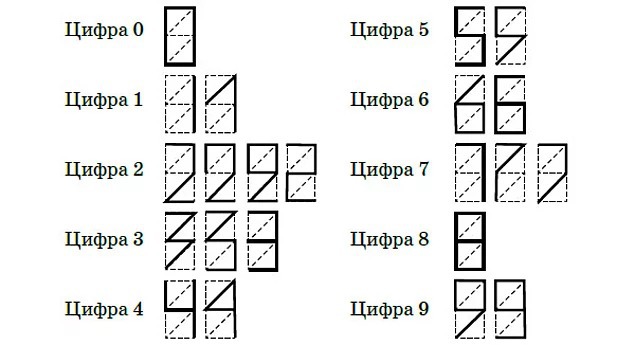
Фотографии печатаются на профессиональных лабораториях Durst Theta с последующей накаткой на пенокартон Kapafix толщиной 5мм, усиленный алюминиевой фольгой. Цена крепежа для крепления на леску – 50р., заказывается отдельно.
Печать фотографий с накаткой на пенокартон:
| Размер | Цена |
| 30 x 40 | 820 р. |
| 30 x 45 | 920 р. |
| 40 x 50 | 1360 р. |
| 40 x 60 | 1640 р. |
| 50 x 60 | 2040 р. |
| 50 x 70 | 2380 р. |
| 60 x 90 | 3670 р. |
| 70 x 100 | 4760 р. |
Средние сроки готовности – 1-3 рабочих дня.
10*15см – 30 р.
15*20см – 40 р.
20*30см – 90 р.
30*40см – 150 р.
Средние сроки готовности – 1-2 будних дня.
Как заказать цифровую печать фотографий?1. Создайте папку на Вашем компьютере с нужным размером готовых отпечатков, например, ’20х30′. Если часть фотографий должна быть 10х15, а другая – 30х40, то создайте две папки с двумя соответствующими именами.
Имейте в виду, что при сканировании 35мм фотопленки в лаборатории FOQUS LAB вы можете напечатать фотографии максимального размера 20х30см при стандартном разрешении (3000 х 2000 pxls) или 40х60см при заказе скана в высоком разрешении (6000 х 4000 pxls), а также фотографии вплоть до 70х100см при заказе покадрового сканирования на Nikon 9000. При сканировании пленки 120 типа в нашей лаборатории Вы получаете файлы в размере, достаточном для печати 20х20см при стандартном разрешении и 40х40 при высоком.
При сканировании пленки 120 типа в нашей лаборатории Вы получаете файлы в размере, достаточном для печати 20х20см при стандартном разрешении и 40х40 при высоком.
2. Скопируйте в папку фотографии, которые хотите напечатать.
3. Сожмите папку в Zip или Rar архив и прикрепите к электронному письму на [email protected]
В теле письма напишите, пожалуйста:
– Ваше имя и фамилию
– номер телефона
– на какой бумаге, матовой или глянцевой, Вы хотите напечатать снимки
– печать c полями/без полей (обратите внимание, что если Ваши фотографии не соответствуют выбранному Вами формату бумаги, они будут обрезаны под формат. Чтобы этого избежать, следует заказать печать с полями и указать это в комментариях. К стандартным, некадрированным ‘пленочным’ кадрам это не относится: их пропорции, как правило, соответствуют стандартным форматам, перечисленным выше в разделе цен на услуги.
– количество каждой фотографий (например, по 1шт.)
– оставьте любые другие комментарии к заказу (например, ‘печать с накаткой на пенокартон’)
5. В теме письма укажите ‘Заказ на печать’
6. Отправьте письмо с вложенным архивом на электронный адрес лаборатории: [email protected]
7. Как только мы проверим и подготовим файлы для печати, Вам придет уведомление на почту с итоговой стоимостью заказа и ориентировочными сроками готовности. По готовности заказа Вы получите SMS на указанный номер телефона и уведомление на e-mail.[:en]Мы можем напечатать Ваши фотографии вручную, непосредственно с пленки, а можем – цифровым способом напечатать отсканированные фотографии на фото-принтере. А если вам нужна накатка ваших фотографий на пенокартон, такая услуга также есть в нашей лаборатории.
Ручная оптическая печать – процесс создания позитивного изображения на светочувствительной фотобумаге с негатива методом фотоувеличения. Печать фотографий оптическим способом происходит в специально оборудованной темной комнате при нашей лаборатории. На фотобумаге после экспонирования создаётся скрытое изображение, далее после лабораторной обработки (проявления, фиксирования, промывки и т. д.) получаем фотографию. Сначала – несколько тестовых отпечатков для нахождения нужной экспозиции, после чего получаем готовые отпечатки.
д.) получаем фотографию. Сначала – несколько тестовых отпечатков для нахождения нужной экспозиции, после чего получаем готовые отпечатки.
Ручная печать черно-белых фотографий осуществляется с фотопленки методом фотоувеличения. Печать возможна на полуматовой бумаге Ilford с пластиковой основой (RC) и на матовой или глянцевой бумаге Ilford с баритовой основой (FB), цена за лист:
| RC | FB | |
| 10 x 15 | 300 | 500 |
| 13 x 18 | 430 | 730 |
| 18 x 24 | 440 | 740 |
| 20 x 30 | 450 | 760 |
Другие форматы и детали согласовываются индивидуально!
Контактная печать (контакт-принты) – 500р./пленка (1 лист 20*30)
Срок готовности ручной черно-белой печати от 1 недели и согласовываются индивидуально.
Как напечатать текст надстрочного и подстрочного текста в страницах для Mac OS X
Если вам нужно набирать индексы или надстрочные символы на Mac, вы обнаружите, что это просто вопрос о желаемом сдвиге базовой линии в приложениях Pages или TextEdit в OS X. Вы также можете настроить исходный сдвинутый текст выше или ниже, чтобы удовлетворить ваши потребности.
Ввод текста подстрочного текста и надстрочного текста в Mac OS X
Это работает как в приложении Pages app, так и в приложении TextEdit для ОС X. Поэтому будьте в любом из этих приложений и начните вводить, как обычно, тогда, когда вы попадаете в точку, где вы хотите вставить надстрочный или индексный текст, выполните следующие действия:
- Выдвиньте меню «Формат» и перейдите в «Шрифт»,
- Выберите подменю «Базовая линия» и выберите «Верхний индекс» или «Подстрочный индекс»,
- Введите нужный текст, который будет подстрочным или надстрочным, затем вернитесь в одно и то же меню и выберите «Использовать по умолчанию», чтобы вернуться к нормальному исходному тексту
Вы также можете использовать опции «Поднять» или «Нижняя» в подменю «Базисный шрифт», чтобы создать более преувеличенный верхний индекс или индекс, что может быть полезно для некоторых шрифтов, где изменение базовой линии менее очевидно.
Эта графика из Википедии помогает прояснить различия между двумя, индексом сверху и верхним индексом внизу, от «базовой линии», который является стандартным размещением напечатанного текста:
Трюк для настройки baselining работает одинаково в приложении Pages app и TextEdit OS X. Подстрочный индекс и надстрочный индекс также поддерживаются в пакете Microsoft Office для Mac. Говоря о Office, если вы пытаетесь ввести текст с измененным исходным текстом в Pages, а затем сохраните файл как Word .doc, вы можете столкнуться с некоторыми проблемами форматирования, в зависимости от версии Word и Office, используемой на другом конце. В таких ситуациях лучше всего сохранить файл в формате PDF и отправить его на другие платформы. Конечно, печать лишних шрифтов на физическом документе не должна быть проблемой вообще.
Использование сочетаний клавиш для надстрочного и подстрочного в приложении для страниц
Гораздо предпочтительный способ быстрого ввода индексов и надстроек на Mac состоит из двух специальных сочетаний клавиш в приложении Pages.
- Текст надстрочного текста: Command + Control + =
- Текстовое нажатие клавиши: Command + Control + —
В случае, если это неясно, это Command + Control + Plus для надстрочного индекса, а Command + Control + Minus для индекса. Повторное нажатие последовательности клавиш переместит следующий напечатанный текст на обычную базовую линию.
Обратите внимание, что эти нажатия клавиш ограничены страницами по умолчанию, и они не доступны сразу в TextEdit. Если вы хотите добавить похожие сочетания клавиш в TextEdit или другое приложение для редактирования текста по вашему выбору, вы можете сделать это с помощью «Системные настройки»> «Клавиатуры»> «Ярлыки клавиш», просто выберите комбинацию клавиш, которая не конфликтует с другими.
Быстрое боковое обозначение, использующее надстрочный индекс, не обязательно для ввода символа температуры на Mac, вы можете использовать конкретное нажатие клавиши для ввода символа градуса.
Идеальный почтовый индекс
Игорь Акулич
«Квантик» №1, 2015
В далёком 1971 году Министерство связи (тогда ещё СССР) ввело в обращение почтовые индексы. Иными словами, каждому почтовому отделению был присвоен свой уникальный шестизначный числовой индекс, а на конвертах появился специальный шаблон — так называемый кодовый штамп, содержащий заготовки для шести цифр:
Надо было обвести синим или чёрным цветом нужные линии, чтобы образовались цифры. Но обводить не как кому нравится, а в соответствии с образцом, который имелся на обратной стороне конверта:
При обработке корреспонденции конверты пропускались через сортировальный автомат с оптическим датчиком, который и определял их дальнейшую судьбу — куда какой конверт направится. Такое нововведение позволило существенно ускорить доставку писем (доказательством эффективности системы является тот факт, что она по сей день используется, например, в России).
Но почему изображения цифр имеют именно такой вид, как на образце? Ведь большинство из них можно было нарисовать и по-другому. Неужели они создавались неведомым нам дизайнером, что называется, «от фонаря», лишь бы внешне напоминали привычные символы?
Одним из тех, кто попытался дать научно обоснованный ответ на этот вопрос, был Ярослав Карпов (тогда ещё десятиклассник из тогда ещё Ленинграда), опубликовавший на страницах 11-го номера «Кванта» за 1987 год статью «Оптимальная кодировка почтового индекса». Исходил он из следующих предположений. Сортировальный автомат может, хотя и с очень малой вероятностью, ошибаться, причём не только и даже не столько из-за неисправности самой техники, сколько из-за небрежности человека при заполнении кодового штампа (искривлённые линии, слишком бледный цвет и т. д.). Если автомат ошибётся при распознавании какой-либо цифры, то это может привести к одному из двух исходов:
- Воспринятое устройством ошибочное изображение не совпадет ни с какой из других цифр.
 Это, конечно, неприятно, но не фатально — такое письмо будет перенаправлено на ручную сортировку, и задержка при прохождении корреспонденции окажется не слишком большой.
Это, конечно, неприятно, но не фатально — такое письмо будет перенаправлено на ручную сортировку, и задержка при прохождении корреспонденции окажется не слишком большой. - Воспринятое устройством ошибочное изображение совпадёт с какой-то из других цифр. Это гораздо хуже, потому что письмо будет отправлено в другое место. Учитывая географические масштабы государства (тогдашнего, да и нынешнего), нетрудно понять, что пока разберутся и всё поправят — пройдёт немало времени.
Поэтому важнейшей задачей разработчиков системы индексов должно было быть сведение к минимуму вероятности принять одну цифру за другую. Возможно, с этим и связан именно такой внешний вид цифр в индексах?
Чтобы проверить свою догадку, Ярослав Карпов сначала изобразил всевозможные способы приемлемого изображения цифр. Вот что у него получилось:
Из них можно составить всего 1·2·4·3·2·2·2·3·1·2 = 1152 варианта десяти цифровых «комплектов». Далее Карпов ввёл понятие «расстояние между кодировками», равное количеству несовпадающих отрезков при изображении различных цифр. Возьмём, например, принятое в настоящее время изображение цифр 2 и 5. Расстояние между кодировками этих цифр равно 5, так как у них имеется 5 несовпадающих отрезков (т. е. таких, что у одной из цифр соответствующий отрезок проведён, а у другой — нет). А, скажем, расстояние между кодировками цифр 0 и 8 равно лишь 1, ибо у них расхождение имеет место в единственном отрезке — среднем горизонтальном.
Возьмём, например, принятое в настоящее время изображение цифр 2 и 5. Расстояние между кодировками этих цифр равно 5, так как у них имеется 5 несовпадающих отрезков (т. е. таких, что у одной из цифр соответствующий отрезок проведён, а у другой — нет). А, скажем, расстояние между кодировками цифр 0 и 8 равно лишь 1, ибо у них расхождение имеет место в единственном отрезке — среднем горизонтальном.
Обозначим через p вероятность принятия автоматом проведённого отрезка за «непроведённый» или наоборот. Тогда вероятность правильного распознавания одного отрезка равна 1 − р. Вероятность же принять одну цифру за другую равна pk·(1 − p)9−k, где k — расстояние между кодировками цифр, а 9 — общее количество отрезков. Оно и понятно — чтобы спутать одну цифру с другой, необходимо, чтобы ровно k отрезков (как раз те, в которых изображения различаются) были восприняты с ошибкой, а остальные 9 − k отрезков автомат прочитал верно. Таким образом, устройство принимает двойку за пятёрку (или же пятёрку за двойку) с вероятностью p5·(1 − p)4. Ну, а восьмёрка и ноль имеют шансы быть перепутанными с вероятностью p·(1 − p)8.
Таким образом, устройство принимает двойку за пятёрку (или же пятёрку за двойку) с вероятностью p5·(1 − p)4. Ну, а восьмёрка и ноль имеют шансы быть перепутанными с вероятностью p·(1 − p)8.
Что же далее? Осталось задаться каким-либо «разумным» значением p, после чего для каждого из 1152 наборов найти вероятность спутать каждую пару цифр (а таких пар, как легко видеть, 10·9/2 = 45) и просуммировать все эти вероятности. Полученную сумму можно считать критерием «качества»: чем она больше, тем меньше вероятность отправления письма в другое место при использовании того или иного набора.
Ярослав Карпов всё это проделал, используя компьютер (тогда ещё ЭВМ), для различных значений р. Оказалось, что при p ≤ 0,3 наилучшим является именно тот набор, который используется в настоящее время. А поскольку реальное значение р заведомо не превышает 0,3 (иначе грош цена такой технике), то получается, что разработчики системы шли по такому же пути!
«Конечно, мне было бы приятнее, — отмечает напоследок Ярослав Карпов, — если бы моя программа выявила не принятый на почте набор, а другой: я тогда смог бы предложить заменить принятый набор на свой — лучший». К сожалению, не судьба!
К сожалению, не судьба!
…Однако с тех пор многое изменилось. Прежде всего, появилось множество световых табло в самых разных местах (лифты, светофоры, часы). И как-то автору этой заметки попалось на глаза другое изображение цифры 1, существенно отличающееся от тех, что «обсчитывал» тогдашний десятиклассник. Вот оно:
Как видно, здесь используются два левых вертикальных отрезка, а не правых. И это изображение ничуть не хуже двух других. А раз так, то имеем возможность получить дополнительно к рассмотренным еще 576 наборов. А дальше — дело техники (в данном случае вычислительной). Проверка на компьютере по методике Карпова показала, что существует два набора, которые превосходят используемый в настоящее время. В лучшем из них все цифры изображаются так же, как и ранее, кроме этой самой единицы. Во втором, который чуть хуже (но всё-таки превосходит нынешний), кроме единицы по-другому изображается четвёрка (см. изображения выше). Так что Ярослав, к великому сожалению, чуть-чуть не дотянул до того, чтобы превзойти используемый набор. Обидно!
И хотя справедливость в конце концов восторжествовала (улучшение всё-таки оказалось возможным), обращаться в Министерство мы не станем. Во-первых, переучить миллионы людей — это ох как непросто, а во-вторых — зачем? Ведь, как ни крути, обычная почта в конвертах уверенно и неизбежно уступает место электронной переписке. Ибо прогресс не остановить.
Художник Наталья Гаврилова
Печать на конвертах — Коперник Рязань
Мы предлагаем:
печать конвертов за 1 день; наличный, безналичный расчет;доставка по Рязани;
цветна и черно-белая печать на конвертах. Все форматы — Евро, С6, С5, С4
Конверт не требует описания. Это изделие используется при почтовой переписке или пересылке писем, бумаг, документов, при вручении пригласительных или открыток. Конверт с напечатаным логотипом — это демонстрация безупречного имиджа и продуманного фирменного стиля вашей компании.
В нашей компании можно заказать печать на конвертах любого формата. Самые популярные форматы — это Евро-конверт, конверт для диска, С6, С5, С4. Мы печатаем на ковертах цифровой и офсетной печатью. Небольшие тиражи до 500 конвертов мы можем изготовить уже на следующий день после оформления заказа.
Мы можем разместить на конвертах следующие виды информации:
- логотип организации;
- обратный адрес;
- персональную информацию — ФИО и адреса получателей.
Особо отметим, что мы можем напечатать конверты с индивидуальной информацией о получателе. Мы самостоятельно подставим на конверт ФИО, адрес, индекс получателя письма. А это — и выглядит серьезно и презентабельно, и экономит время ваших сотрудников. Для работы от Вас потребуется предоставить таблицу в электронном виде с получателями писем и их адресами.
Еще один популярный вид — конверт под CD-диск. Сейчас, в век цифровых технологий, многие компании делают презентацию о себе и своих продуктах и передают их заказчику на диске. Это удобно — можно записать видео-обращение, фильм о продукте, презентацию компании, приложить изображения, инструкции, и передать все это на небольшом диске. А диск, упакованный в конверт с символикой компании — это презентабельно, да и диск не потеряется среди других, обезличенных конвертов. На конверте под диск мы можем разместить изображение, логотип, надпись.
Индекс списка Python ()
Метод index () возвращает индекс указанного элемента в списке.
Пример
животных = ['кошка', 'собака', 'кролик', 'лошадь']
# получить индекс 'собака'
index = animals.index ('собака')
печать (индекс)
# Вывод: 1 Синтаксис индекса списка ()
Синтаксис метода list index () :
list.index (элемент, начало, конец)
список параметров index ()
Метод list index () может принимать не более трех аргументов:
- element — элемент для поиска
- start (необязательно) — начать поиск с этого индекса
- конец (необязательно) — поиск элемента до этого индекса
Возвращаемое значение из индекса списка ()
- Метод
index ()возвращает индекс данного элемента в списке. - Если элемент не найден, возникает исключение
ValueError.
Примечание: Метод index () возвращает только первое вхождение соответствующего элемента.
Пример 1. Найти индекс элемента
# список гласных
гласные = ['a', 'e', 'i', 'o', 'i', 'u']
# индекс 'e' в гласных
index = vowels.index ('e')
print ('Индекс e:', индекс)
Выполняется поиск # элемента 'i'
# возвращается индекс первого i
Индекс = гласные.индекс ('я')
print ('Индекс i:', index) Выход
Индекс е: 1 Индекс i: 2
Пример 2: Указатель элемента, отсутствующего в списке
# список гласных
гласные = ['a', 'e', 'i', 'o', 'u']
# индекс 'p' - гласные
index = vowels.index ('p')
print ('Индекс p:', index) Выход
ValueError: 'p' отсутствует в списке
Пример 3: Работа index () с параметрами начала и конца
# список алфавитов
алфавиты = ['a', 'e', 'i', 'o', 'g', 'l', 'i', 'u']
# индекс 'i' в алфавитах
Индекс = алфавиты.index ('e') # 1
print ('Индекс e:', индекс)
# 'i' после поиска по 4-му индексу
индекс = alphabets.index ('i', 4) # 6
print ('Индекс i:', индекс)
# ищется 'i' между 3-м и 5-м индексами
index = alphabets.index ('i', 3, 5) # Ошибка!
print ('Индекс i:', index) Выход
Индекс е: 1 Индекс i: 6 Отслеживание (последний вызов последний): Файл "* lt; string>", строка 13, в ValueError: 'i' отсутствует в списке
Python List insert ()
Метод insert () вставляет элемент в список по указанному индексу.
Пример
# создать список гласных
гласный = ['a', 'e', 'i', 'u']
# 'o' вставляется в индекс 3 (4-я позиция)
vowel.insert (3, 'о')
print ('Список:', гласная)
# Вывод: Список: ['a', 'e', 'i', 'o', 'u'] Синтаксис List insert ()
Синтаксис метода insert () :
list.insert (i, elem)
Здесь элемента вставляется в список по индексу i th .Все элементы после elem смещены вправо.
вставить () Параметры
Метод insert () принимает два параметра:
- index — индекс, куда нужно вставить элемент
- элемент — это элемент, который нужно вставить в список
Примечания:
- Если индекс равен 0, элемент вставляется в начало списка.
- Если index равен 3, индекс вставленного элемента будет 3 (4-й элемент в списке).
Возвращаемое значение из вставки ()
Метод insert () ничего не возвращает; возвращает Нет . Он обновляет только текущий список.
Пример 1: Вставка элемента в список
# создать список простых чисел
простые_числа = [2, 3, 5, 7]
# вставить 11 в индекс 4
простые числа.вставить (4, 11)
print ('Список:', простые_числа) Выход
Список: [2, 3, 5, 7, 11]
Пример 2: Вставка кортежа (как элемента) в список
mixed_list = [{1, 2}, [5, 6, 7]]
# числовой кортеж
number_tuple = (3, 4)
# вставляем кортеж в список
mixed_list.insert (1, набор_числов)
print ('Обновленный список:', смешанный_лист) Выход
Обновленный список: [{1, 2}, (3, 4), [5, 6, 7]] Список Python remove ()
Метод remove () удаляет первый совпадающий элемент (который передается в качестве аргумента) из списка.
Пример
# создать список
простые_числа = [2, 3, 5, 7, 9, 11]
# удалить 9 из списка
prime_numbers.remove (9)
# Обновлен список prime_numbers
print ('Обновленный список:', простые_числа)
# Вывод: обновленный список: [2, 3, 5, 7, 11] Синтаксис списка remove ()
Синтаксис метода remove () :
list.remove (элемент)
remove () Параметры
- Метод
remove ()принимает один элемент в качестве аргумента и удаляет его из списка. - Если элемент
Возвращаемое значение из remove ()
remove () не возвращает никакого значения (возвращает None ).
Пример 1: Удалить элемент из списка
# список животных
животные = ['кошка', 'собака', 'кролик', 'морская свинка']
# 'кролик' удален
animals.remove ('кролик')
# Обновленный список животных
print ('Обновленный список животных:', животные) Выход
Обновленный список животных: [«кошка», «собака», «морская свинка»]
Пример 2: метод remove () для списка с повторяющимися элементами
Если список содержит повторяющиеся элементы, метод remove () удаляет только первый совпадающий элемент.
# список животных
животные = ['кошка', 'собака', 'собака', 'морская свинка', 'собака']
# 'собака' удалена
animals.remove ('собака')
# Обновлен список животных
print ('Обновленный список животных:', животные) Выход
Обновленный список животных: [«кошка», «собака», «морская свинка», «собака»]
Здесь из списка удаляется только первое вхождение элемента «собака» .
Пример 3: Удаление несуществующего элемента
# список животных
животные = ['кошка', 'собака', 'кролик', 'морская свинка']
# Удаление элемента 'рыба'
животные.удалить ('рыба')
# Обновленный список животных
print ('Обновленный список животных:', животные) Выход
Traceback (последний звонок последний):
Файл ".. .. ..", строка 5, в <модуль>
animal.remove ('рыба')
ValueError: list.remove (x): x отсутствует в списке Здесь мы получаем ошибку, потому что список животных не содержит 'рыб' .
- Если вам нужно удалить элементы по индексу (например, четвертый элемент), вы можете использовать метод pop ().
- Кроме того, вы можете использовать оператор Python del для удаления элементов из списка.
Python List index () — GeeksforGeeks
index () — это встроенная функция в Python, которая выполняет поиск заданного элемента с начала списка и возвращает наименьший индекс, в котором появляется элемент.
Пример 1: Найдите индекс элементаСинтаксис:
list_name.index (element, start, end)
Параметры:
- element — Элемент, наименьший индекс которого будет возвращен.
- начало (Необязательно) — позиция, с которой начинается поиск.
- конец (необязательно) — позиция, с которой заканчивается поиск.
Возвращает:
Возвращает наименьший индекс, в котором появляется элемент.
Ошибка:
При поиске любого элемента, которого нет, возвращается ValueError
Python3
|
3
0
Пример 1.1
Python3
list1 = [ 1 , 2 , 0003 0004 , 1 , 1 , 4 , 5 ]
печать (списокиндекс ( 4 , 4 , 8 ))
печать (list1.index ( 1 , 7 ))
list2 = [ 'cat' , 'bat' , '' mat '9000 cat4 ,
'get' , 'cat' , 'sat' , 'pet' ]
(список2.index ( 'cat' , 2 , 6 ))
Выход:
7
4
3
Пример 1.2
Python3
list1 = [ 1 , 2 , , , , , 8 , 7 ], ( 'кошка' , 'летучая мышь' )]
распечатать списокindex ([ 9 , 8 , 7 ]))
print (list1.index (( 'cat' 'cat' 'летучая мышь' )))
Выход:
3
4
Пример 2: Индекс элемента, отсутствующего в списке (ValueError) Python3
list1 = [ 1 , 3 , 4 , 1 , 1 , 1 , 4 0003, 000 000
печать (list1.index ( 10 ))
Вывод:
Отслеживание (последний звонок последний):
Файл "/home/b910d8dcbc0f4f4b61499668654450d2.py", строка 8, в
печать (list1.index (10))
ValueError: 10 отсутствует в списке Пример 3: Когда переданы 2 аргумента Когда два аргумента передаются в индексной функции, первый аргумент обрабатывается как элемент для поиска, а второй аргумент - это индекс из где начинается поиск.
list_name.index (элемент, начало)
Python3
list1 = [ 6 , 0003 0003 8, 0009 6 , 1 , 2 ]
печать (list1.index ( 6 )
000
Вывод:
3
Пример 4: Конечный индекс, переданный как аргумент, не включен
Третий аргумент, который является концом, сам по себе не входит в диапазон от начала до конца, т.е.e поиск происходит от начала до конца-1 индекса.
Python3
список1 = [ 6 , 2 , 14 000 0003 ; Вывод:
Traceback (последний вызов последний):
Файл "/ home / 3cbe5b7d0595ab3f8564f16af7a15172.py ", строка 9, в
печать (list1.index (9, 1, 4))
ValueError: 9 отсутствует в списке
Пример 4.1
Python3
list1 = [ 6 , , , , , 8 , 9 , 10 ]
печать (list1.index ( 9 , 1 , 5 ))
Выход:
4
Внимание компьютерщик! Укрепите свои основы с помощью курса Python Programming Foundation и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS . И чтобы начать свое путешествие по машинному обучению, присоединяйтесь к Машинное обучение - курс базового уровня
python - Поиск индекса элемента в списке
Поиск индекса элемента в списке, содержащем его в Python
Для списка ["foo", "bar", "baz"] и элемента в списке "bar" , какой самый чистый способ получить его индекс (1) в Python?
Ну, конечно, есть метод index, который возвращает индекс первого вхождения:
>>> l = ["foo", "bar", "baz"]
>>> л.индекс ('бар')
1
У этого метода есть пара проблем:
- , если значение отсутствует в списке, вы получите
ValueError - , если в списке присутствует более одного значения, вы получите индекс только для первого
Без значений
Если значение могло отсутствовать, вам нужно отловить ValueError .
Вы можете сделать это с помощью определения многоразового использования, например:
индекс определения (a_list, значение):
пытаться:
вернуть a_list.индекс (значение)
кроме ValueError:
return None
И используйте это так:
>>> print (index (l, 'quux'))
Никто
>>> print (index (l, 'bar'))
1
Обратной стороной этого является то, что вы, вероятно, будете проверять, является ли возвращаемое значение или не Нет:
результат = индекс (a_list, значение)
если результат не равен None:
do_something (результат)
В списке более одного значения
Если у вас может быть больше вхождений, вы получите , а не , получите полную информацию со списком .индекс :
>>> l.append ('бар')
>>> l
['foo', 'bar', 'baz', 'bar']
>>> l.index ('bar') # с индексом 3 ничего нет?
1
Вы можете перечислить в виде списка индексы:
>>> [индекс для индекса, v в enumerate (l), если v == 'bar']
[1, 3]
>>> [индекс для индекса, v в enumerate (l), если v == 'boink']
[]
Если у вас нет вхождений, вы можете проверить это с помощью логической проверки результата или просто ничего не делать, если вы перебираете результаты:
indexes = [индекс для индекса, v в enumerate (l), если v == 'boink']
для индекса в индексах:
do_something (индекс)
Улучшенный обмен данными с пандами
Если у вас есть панды, вы можете легко получить эту информацию с помощью объекта Series:
>>> импортировать панд как pd
>>> серия = pd.Серия (l)
>>> серии
0 фу
1 бар
2 баз
3 бар
dtype: объект
Проверка сравнения вернет серию логических значений:
>>> series == 'bar'
0 ложь
1 Верно
2 ложь
3 Верно
dtype: bool
Передайте эту серию логических значений в серию через нотацию нижнего индекса, и вы получите только соответствующие элементы:
>>> series [series == 'bar']
1 бар
3 бар
dtype: объект
Если вам нужны только индексы, атрибут index возвращает серию целых чисел:
>>> серия [series == 'bar'].показатель
Int64Index ([1, 3], dtype = 'int64')
И если вы хотите, чтобы они были в списке или кортеже, просто передайте их конструктору:
>>> список (series [series == 'bar']. Index)
[1, 3]
Да, вы также можете использовать понимание списка с enumerate, но, на мой взгляд, это не так элегантно - вы проводите тесты на равенство в Python, вместо того, чтобы позволять встроенному коду, написанному на C, обрабатывать это:
>>> [i для i, значение в enumerate (l) if value == 'bar']
[1, 3]
Проблема XY - это вопрос о вашей попытке решения, а не о вашей реальной проблеме.
Как вы думаете, зачем вам нужен индекс для элемента в списке?
Если вы уже знаете значение, почему вас волнует, где оно находится в списке?
Если значение отсутствует, то перехват ValueError будет довольно подробным - и я предпочитаю этого избегать.
Я обычно все равно перебираю список, поэтому я обычно сохраняю указатель на любую интересную информацию, получая индекс с помощью enumerate.
Если вы изменяете данные, вам, вероятно, следует использовать pandas - у которого есть гораздо более элегантные инструменты, чем чистые обходные пути Python, которые я показал.
Я не помню, чтобы мне понадобился list.index . Однако я просмотрел стандартную библиотеку Python и увидел несколько отличных применений для нее.
В idlelib его много, много применений, для графического интерфейса пользователя и анализа текста.
Модуль с ключевыми словами использует его для поиска маркеров комментариев в модуле для автоматического восстановления списка ключевых слов в нем посредством метапрограммирования.
В Lib / mailbox.py кажется, что он используется как упорядоченное сопоставление:
список_ключей [список_ключей.index (old)] = new
и
del key_list [key_list.index (ключ)]
В Lib / http / cookiejar.py, похоже, используется для получения следующего месяца:
мес = MONTHS_LOWER.index (mon.lower ()) + 1
В Lib / tarfile.py аналогично distutils для получения фрагмента до элемента:
members = members [: members.index (tarinfo)]
В Lib / pickletools.py:
numtopop = before.index (markobject)
Что общего у этих способов использования, так это то, что они, похоже, работают со списками ограниченного размера (что важно из-за времени поиска O (n) для списка ).index ), и они в основном используются при синтаксическом анализе (и пользовательском интерфейсе в случае простоя).
Хотя для него есть варианты использования, они довольно редки. Если вы обнаружите, что ищете этот ответ, спросите себя, является ли то, что вы делаете, наиболее прямым использованием инструментов, предоставляемых языком для вашего варианта использования.
УКАЗАТЕЛЬ ПЕЧАТИ
Утилита PRINT INDEX сообщает о структуре системных индексов и индексированных наборов. Используя утилиту PRINT INDEX, вы можете просмотреть:
Количество уровней в индексе
Содержимое фиксированной и переменной частей одной или нескольких записей SR8 в индексе
Объем доступного места на странице, содержащей каждый SR8 в индексе
В этой статье описывается следующая информация:
Отчет об индексах в сегменте
DBAREAD
Область, содержащая индекс, и области, содержащие записи, на которые ссылается индекс
►►─── ИНДЕКС ПЕЧАТИ ─┬─ имя набора
спецификации набора ──────────────┬────────────►
└─ SR8 ключ-вхождения-1
── вариант-отчета
────┘
►────┬─────────────────────────────────┬──┬───────── ──────┬────────────────────►◄
├─ ТОЛЬКО ◄───────────────────────── ├─ ДЕСЯТИЧНЫЙ ───┤
├─ ДЕРЕВО ──────────────────────────┤ ├─ HEX ────────┤
├─ ПОЛНЫЙ ────────────────────────── └─ ТЕРСА ──────┘
├─ НОГА ───────────────────────────┤
├─ РЕЗЮМЕ ───┬─────────────┬─────
│ ├─ ТОЛЬКО ◄──── │
│ └─ ПОДРОБНО ─┘ │
└─┬─ СЛЕДУЮЩИЙ ──┬─┬──────────────────
├─ PRIOR ─┤ └─ номер уровня
─┘
└─ LVL ───┘
Расширение набора-спецификаций
►►──┬── SEGMENT segment-name
──┬───────────────────────────────── ────────────────►
└─ DBNAME db-name
────────
►── ИСПОЛЬЗОВАНИЕ имени-подсхемы ─┬────────────────────────────────┬──────── ────────┬─►
│ ├─ ВЛАДЕЛЕЦ ──┬─ ключ-2 появления-2
─┘ │
│ └─ УЧАСТНИК ─┘ │
│ │
└─ ТАБЛИЦА имя-схемы.table-id
─┬──────────────────────────────────────────
├─ ССЫЛКА ──┬ ROWID ключ-вхождение-2
─┘
└─ ССЫЛКИ ─┘
►─┬─ report-option ─────────────────┬─────────────────────────── ────────────────►◄
├─ ПОЛНЫЙ ──────────────────────────
└─ РЕЗЮМЕ ───┬─────────────┬─────
├─ ТОЛЬКО ◄────┤
└─ ПОДРОБНО ─┘
Расширение события-ключ-1
►►─┬───────────────┬─┬─ X'hex-database-key'──┬───────────────── ────────────►◄
└─ группа-страниц: ─┘ └─ номер-страницы: номер-строки
───┘
Расширение появления-ключ-2
►►──┬─ X'hex-database-key'──┬─────────────────────────────────── ────────────►◄
└─ номер страницы: номер строки
───┘
Расширение опции отчета
►►────┬──────────────────────────────────────────── ──────────────────────────►◄
ТОЛЬКО ├─ ◄─────────────────────────
├─ ДЕРЕВО ──────────────────────────
├─ НОГА ───────────────────────────┤
├─ ДАЛЕЕ ──┬──┬────────────────┬───
├─ PRIOR ─┤ └─ номер уровня
─┘
└─ LVL ───┘
- Задает имя принадлежащего системе индекса или индексированного набора, по которому оператор PRINT INDEX должен сообщить.При обработке индекса, принадлежащего системе, обработка начинается с первой записи SR8 в наборе SR7-SR8.
-
СЕГМЕНТ
Задает сегмент, содержащий структуры индекса, о которых необходимо сообщить. При использовании опции FULL или при указании dbkey начального члена область члена также должна существовать в этом сегменте. - Задает имя сегмента.
-
ИМЯ БД
Задает базу данных, содержащую структуры индекса, для которых необходимо создать отчет. -
имя базы данных
Задает имя базы данных. - Задает имя подсхемы, в которую включен именованный индексированный набор.
- Задает имя таблицы.
-
ССЫЛКА ROWID
Для именованной таблицы указывает утилите PRINT INDEX сообщить о вхождении индекса, владельцем которого является указанная строка, идентифицированная ключом вхождения . -
ССЫЛКА ROWID
Для именованной таблицы предписывает утилите PRINT INDEX сообщить о вхождении индекса, содержащем идентификатор строки ссылающейся строки, идентифицированной с помощью ключа вхождения . - Задает шестнадцатеричный ключ базы данных для записи владельца или члена в указанном индексированном наборе.
- Задает номер страницы записи владельца или члена в указанном индексированном наборе.
- Задает номер строки записи владельца или члена в указанном индексированном наборе.
-
SR8
Определяет индекс, который должен быть обработан, путем указания индекса записи SR8 в индексе. - Определяет группу страниц СЕГМЕНТА, где находится индекс.
- Задает шестнадцатеричный ключ базы данных для записи SR8.
- Задает номер страницы записи SR8.
- Задает номер строки записи SR8.
- ТОЛЬКО Указывает утилите PRINT INDEX сообщать только о записи SR8, используемой в качестве точки входа в индекс. По умолчанию используется ТОЛЬКО, если вы не указываете часть структуры индекса для отчета.
-
ДЕРЕВО
Указывает утилите PRINT INDEX сообщать обо всех записях SR8 в индексе, начиная с SR8 верхнего уровня.SR8 обрабатываются по следующим указателям. -
ПОЛНАЯ
Указывает утилите PRINT INDEX сообщать: Все записи SR8 в индексе, начиная с SR8 верхнего уровня. SR8 обрабатываются по следующим указателям.
Ключ базы данных, значение указателя индекса и потерянное состояние каждой записи элемента в индексе. Записи участников обрабатываются путем перехода на нижний уровень индекса.
-
НОЖКА
Указывает служебной программе PRINT INDEX сообщать о записях SR8, связанных указателями вверх, начиная с SR8, используемого в качестве точки входа в индекс.Для несортированного индекса или для записи SR8, которая является SR8 верхнего уровня в отсортированном индексе, указание LEG имеет тот же эффект, что и указание ONLY. -
СЛЕДУЮЩИЙ
Указывает утилите PRINT INDEX сообщать о записях SR8, связанных указателями next на одном уровне индекса, начиная с SR8, используемого в качестве точки входа в индекс. -
ПРИОР
Указывает утилите PRINT INDEX сообщать о записях SR8, связанных предшествующими указателями на одном уровне индекса, начиная с SR8, используемого в качестве точки входа в индекс. -
LVL
Указывает, что утилита PRINT INDEX будет сообщать обо всех записях SR8 на одном уровне индекса. - Задает уровень индекса для отчета; целое число в диапазоне от 0 до 255. По умолчанию, если вы не укажете уровень индекса, утилита PRINT INDEX сообщает о SR8 на уровне записи SR8, используемой в качестве точки входа в индекс.
-
РЕЗЮМЕ
Запрашивает сводный отчет для целевого индекса.Сводный отчет состоит из трех частей: Часть 1 (заголовок) содержит общую информацию об определении индекса.
Часть 2 (основная часть) предоставляет информацию о вхождениях владельцев индекса. Индекс, принадлежащий системе, содержит одного владельца индекса; принадлежащий пользователю индекс может содержать более одного владельца индекса.
Часть 3 (обзор индекса) предоставляет глобальную статистическую информацию только для индекса, принадлежащего пользователю.
Сводный отчет по системному индексу содержит части 1 и 2.Сводный отчет по индексу, принадлежащему пользователю, всегда содержит части 1 и 3. Часть 2 включается только в подробный сводный отчет.- ТОЛЬКО Запрашивает сводный отчет с частями 1 и 3 для целевого пользовательского индекса. Этот параметр игнорируется для индекса, принадлежащего системе. ТОЛЬКО по умолчанию.
-
ПОДРОБНЕЕ
Запрашивает сводный отчет с частями 1, 2 и 3 для целевого пользовательского индекса. Этот параметр игнорируется для индекса, принадлежащего системе.
-
ДЕСЯТИЧНЫЙ
Указывает утилите PRINT INDEX печатать как фиксированные, так и переменные части каждой записи SR8 в отчете. Символические ключи в переменной части каждого SR8 печатаются в десятичном (отображаемом) формате.DECIMAL используется по умолчанию, если вы не указываете способ, которым должно быть напечатано содержимое SR8 в указателе. -
HEX
Указывает утилите PRINT INDEX печатать как фиксированные, так и переменные части каждой записи SR8 в отчете.Символьные ключи в переменной части каждого SR8 печатаются в шестнадцатеричном формате. -
ТЕРСЕ
Указывает утилите PRINT INDEX печатать только фиксированную часть каждой записи SR8 в отчете.
Как отправить отчет PRINT INDEX
Вы передаете оператор PRINT INDEX, используя средство пакетной команды или средство онлайн-команд.
Утилита PRINT INDEX может помочь вам определить, нужно ли перестраивать индекс.Например, вам следует подумать о перестроении индекса, когда служебный отчет PRINT INDEX по индексу указывает одно из следующих значений:
Число уровней индекса больше, чем ожидалось для исходной структуры индекса.
Двадцать пять или более процентов членских записей являются сиротами.
Индекс можно перестроить с помощью MAINTAIN INDEX или TUNE INDEX. Для получения дополнительной информации о восстановлении индекса и индексировании в целом см. CA IDMS Database Administration Section
. Вывод PRINT INDEX без параметра SUMMARY пропорционален количеству элементов индекса, о которых сообщается. Если PRINT INDEX запускается онлайн или пакетно через CV, вывод буферизируется с нуля. Если рабочая область не может вместить весь вывод, PRINT INDEX завершается ошибкой с завершением задачи.
Шестнадцатеричное отображение символьных клавиш
Параметр HEX оператора SET / SR8 полезен, когда символический ключ для индекса является не отображаемым типом данных, например двоичным или упакованным.
Вы можете использовать DBNAME вместо SEGMENT в любое время. Вы должны использовать его, когда член индекса находится в сегменте, отличном от сегмента структуры индекса, и используется опция FULL, или вы указываете начальный dbkey MEMBER.
Когда вы отправляете утилиту PRINT INDEX через средство пакетных команд, JCL для выполнения средства должен включать операторы для определения:
Файлы базы данных, содержащие индексы и записи элементов, к которым необходимо получить доступ.
Дополнительные сведения об общем JCL, используемом для выполнения средства пакетной команды, см. В разделе для вашей операционной системы в этом разделе.
В следующем примере утилита PRINT сообщает об EMP-IDX-SET с использованием опции FULL.
ПЕЧАТЬ ИНДЕКС "EMP-IDX-SET" ИМЯ БД VLDBDBN ИСПОЛЬЗОВАНИЕ VLDBSUBC FULL;
Печать нижнего уровня индекса
В следующем примере утилита PRINT сообщает о COV-IDX-SET с помощью параметров LEVEL и TERSE.
ПЕЧАТЬ УКАЗАТЕЛЯ "COV-IDX-SET" СЕГМЕНТА VLDBSPG1 ИСПОЛЬЗУЯ ЧЛЕН VLDBSUBC X'013 'LVL 0 TERSE;
Печать отдельной записи SR8
В следующем примере утилита PRINT сообщает о конкретной записи SR8.
УКАЗАТЕЛЬ ПЕЧАТИ SR8 5: 80130: 03 СЛЕДУЮЩИЙ 2 HEX;
Печать индекса из базы данных, определенной SQL
В следующем примере служебная программа PRINT сообщает об индексе EMP-COVERAGE, который является частью таблицы SQLSPG.EMPLOYEE.
ПЕЧАТЬ ИНДЕКС "EMP-COVERAGE" СЕГМЕНТ VLDBSPG1 ТАБЛИЦА SQLSPG.EMPLOYEE SUMMARY;
Печать сводного отчета индекса
В следующем примере утилита PRINT сообщает об индексе DEPT_EMPL с помощью параметра SUMMARY.
ПЕЧАТЬ ИНДЕКСА DEPT_EMPL SEGMENT USERDB TABLE DEMO.DEPT SUMMARY;
Печать сводного отчета REFERENCING ROWID индекса
В следующем примере утилита PRINT сообщает о вхождении индекса, содержащем идентификатор строки, на которую указывает ссылка X'013 '.
ПЕЧАТЬ ИНДЕКС "COV-IDX-SET" ТАБЛИЦА СЕГМЕНТА VLDBSPG1 SQLSPG.COVERAGE ССЫЛКА НА ROWID X'013
'РЕЗЮМЕ; Утилита PRINT INDEX генерирует следующий отчет после успешного выполнения оператора в предыдущем примере «Печать всего индекса».
IDMSBCF 18.0 CA Средство пакетных команд IDMS мм / дд / гг
УКАЗАТЕЛЬ ПЕЧАТИ "EMP-IDX-SET"
DBNAME VLDBDBN
ИСПОЛЬЗОВАНИЕ VLDBSUBC FULL;
SET = EMP-IDX-SET OWNER = SR7 ГРУППА СТРАНИЦ = 2 ЗАПИСИ НА СТРАНИЦУ = 255
ODBK = 01394301 SR8 N01394303 SR8 P01394306 ASC CUSH = 12 SYM TKL = 3 COMP
УЧАСТНИК = ГРУППА СТРАНИЦЫ = 1 ЗАПИСИ НА СТРАНИЦУ = 255
L1 01394303 ЧИСЛО = 5 U = FFFFFFFF N = 01394302 P = 01394301 RECL = 224 SPA = 3164
01394302 0028 01394304 0053 01394307 0106 01394305 0329 01394306 0479
L0 01394302 NUME = 15 U = 01394303 N = 01394304 P = 01394303 RECL = 184 SPA = 3164
0138DF01 0001 0138DE01 0003 0138CE01 0004 0138D801 0007 0138C501 0011 0138D401 0013 0138D101 0015
0138CE02 0016 0138DE02 0019 0138DE03 0020 0138DE04 0021 0138DE05 0023 0138DE06 0024 0138DE07 0027
0138DE08 0028
01394304 ЧИСЛО = 10 ORPH = 8 U = 01394303 N = 01394307 P = 01394302 RECL = 140 SPA = 3164
..
.
MEM 0138DF01 U = 01394302
0138DE01 U = 01394302
0138CE01 U = 01394302
0138D801 U = 01394302
0138C501 U = 01394302
0138D401 U = 01394302
0138D101 U = 01394302
0138CE02 U = 01394302
0138DE02 U = 01394302
0138DE03 U = 01394302
..
.
0138CF02 * ORPHAN * OF * U = 01394305
0138CF03 * ORPHAN * OF * U = 01394305
0138D107 U = 01394306
0138D105 * ОРФАН * OF * U = 01394305
0138D108 U = 01394306
0138D106 U = 01394306
0138DB05 U = 01394306
0138DF03 U = 01394306
0138DF04 U = 01394306
0138D807 U = 01394306
0138DB04 U = 01394306
ИТОГО SR8 = 6
Статус = 0 SQLSTATE = 00000
Печать нижнего уровня индекса
В следующем отчете показано использование опций LVL и TERSE для запроса печати нижнего уровня индекса.
IDMSBCF 18.0 CA Средство пакетных команд IDMS мм / дд / гг
УКАЗАТЕЛЬ ПЕЧАТИ "COV-IDX-SET"
СЕГМЕНТ VLDBSPG1 ИСПОЛЬЗУЕТ VLDBSUBC
MEMBER X'013 'LVL 0 TERSE;
НАБОР = COV-IDX-НАБОР ВЛАДЕЛЬЦА = ГРУППА СТРАНИЦ SR7 = 5 ЗАПИСЕЙ НА СТРАНИЦУ = 255
ODBK = 013
SR8 N013 SR8 P013 UNS CUSH = 4
УЧАСТНИК = ГРУППА СТРАНИЦЫ = 5 ЗАПИСЕЙ НА СТРАНИЦУ = 255
L0 013 ЧИСЛО = 4 U = FFFFFFFF N = 013 P = 013 RECL = 52 SPA = 3820
013
ЧИСЛО = 70 U = FFFFFFFF N = 013 P = 013 RECL = 316 SPA = 3820
ИТОГО SR8 = 2
Статус = 0 SQLSTATE = 00000
Печать отдельных записей SR8
В следующем отчете показано использование опции SR8 для запроса печати определенной записи SR8.
IDMSBCF 18.0 CA Средство пакетных команд IDMS мм / дд / гг
УКАЗАТЕЛЬ ПЕЧАТИ SR8 5: 80130: 03 СЛЕДУЮЩИЙ 2 HEX;
НАБОР = COV-IDX-НАБОР ВЛАДЕЛЬЦА = ГРУППА СТРАНИЦ SR7 = 5 ЗАПИСЕЙ PE
R PAGE = 255
ODBK = 013
SR8 N013 SR8 P013 UNS CUSH = 4
L0 013 ЧИСЛО = 4 U = FFFFFFFF N = 013 P = 013 RECL = 52 СПА = 3820
0139044A 013 013 013 013
ЧИСЛО = 70 U = FFFFFFFF N = 013 P = 013 RECL = 316 СПА = 3820
013 013 013 013 013 013 013 0139043F 0139043E 0139043D 0139043C 0139043B
0139043A 013 013 013 013 013 013 013 013 013 013 0139042F
0139042E 0139042D 0139042C 0139042B 0139042A 013 013 013 013 013 013 013 013 013 013 0139041F 0139041E 0139041D
0139041C 0139041B 0139041A 013 013 013 013 013 013 013 013 013 013
0139040F 0139040E 0139040D 0139040C 0139040B
0139040A 013 013 013 013
013 013 013 013 013 ИТОГО SR8 = 2
Печать индекса из базы данных, определенной SQL
В следующем примере представлен отчет с использованием параметра FULL для индекса, определенного SQL.
УКАЗАТЕЛЬ ПЕЧАТИ "COV-IDX-SET" СЕГМЕНТ VLDBSPG1
ТАБЛИЦА SQLSPG.COVERAGE FULL;
НАБОР = COV-IDX-НАБОР ВЛАДЕЛЬЦА = ГРУППА СТРАНИЦ SR7 = 5 ЗАПИСЕЙ НА СТРАНИЦУ = 255
ODBK = 013
SR8 N013 SR8 P013 UNS CUSH = 4
УЧАСТНИК = ГРУППА СТРАНИЦЫ = 5 ЗАПИСЕЙ НА СТРАНИЦУ = 255
L0 013 ЧИСЛО = 4 U = FFFFFFFF N = 013 P = 013 RECL = 52 SPA = 3820
0139044A 013 013 013 013
ЧИСЛО = 70 U = FFFFFFFF N = 013 P = 013 RECL = 316 SPA = 3820
013 013 013 013 013 013 013 0139043F 0139043E 0139043D 0139043C 0139043B
..
. MEM 0139044A U = 013 013 U = 013 013 U = 013 013 U = 013 013 U = 013 …
013
U = 013 013
U = 013 013
U = 013 013 U = 013
013
U = 013
ИТОГО SR8 = 2
Печать сводного отчета индекса
В следующем отчете показано использование опции SUMMARY для запроса печати индекса, принадлежащего пользователю.
УКАЗАТЕЛЬ ПЕЧАТИ "EMP-COVERAGE" СЕГМЕНТ VLDBSPG1
ТАБЛИЦА SQLSPG.EMPLOYEE SUMMARY;
Имя набора: EMP-COVERAGE
IBC 70 Рабочий объем 0
Вариант сортировки НЕ СОРТИРОВКА Длина ключа Н / Д
Дубликаты ПЕРВОЕ сжатие Нет
ВЛАДЕЛЕЦ: СОТРУДНИК
ОБЛАСТЬ VLDBSPG1.EMPL-AREA Нижняя страница (SUB- 80056
Размер страницы 4276 Высокая ПЛОЩАДЬ страницы) 80100
Группа страниц 5 записей на странице 255
УЧАСТНИК: ПОКРЫТИЕ Установить членство Необязательно Автоматически
Расположен индекс VIA Да Displ't 0 Индекс связан
ОБЛАСТЬ VLDBSPG1.COVE-AREA Низкая страница (SUB- 80106
Размер страницы 4276 Высокая ПЛОЩАДЬ страницы) 80150
Группа страниц 5 записей на странице 255
Обзор индекса
Кол-во вхождений собственников 56
Кол-во вхождений собственников 56
Кол-во пустующих хозяев 55 98.2%
Кол-во смещенных SR8 верхнего уровня 0 0,0%
Количество SR8: Всего 2
Среднее 0,0
Наивысший 2-й владелец X'0138D404 '
Мин. количество SR8: всего 2
Среднее 0,0
Наивысший 2-й владелец X'0138D404 '
Количество уровней: Среднее 0.0
Наивысший 1 Владелец X'0138D404 '
Мин. кол-во уровней: Среднее 0,0
Наивысший 1 Владелец X'0138D404 '
Кол-во страниц: в среднем 0,0
Наивысший 1 Владелец X'0138D404 '
Мин. кол-во страниц: в среднем 0,0
Наивысший 1 Владелец X'0138D404 '
Количество обращений с детьми-сиротами 0
Кол-во детей-сирот: Всего 0 0.0%
Самый высокий 0 Владелец *** N / A ***
Общий размер всех SR8 368
Размер наибольшего SR8 316
Распределение уровней индекса
.... + .... 20 ... + .... 40 ... + .... 60 ... + .... 80 ... + ....
2+ | 0 0.0%
1 | + 1 1,7%
0 | ********************************************** * - 55 98,2%
Распределение минимальных уровней индекса
.... + .... 20 ... + .... 40 ... + .... 60 ... + .... 80 ... + ....
2+ | 0 0,0%
1 | + 1 1,7%
0 | ********************************************** * - 55 98,2%
Распределение количества SR8
.... + .... 20 ... + .... 40 ... + .... 60 ... + .... 80 ... + ....
3+ | 0 0,0%
2 | + 1 1,7%
1+ | 0 0,0%
0 | ********************************************** * - 55 98.2%
Распределение количества участников индекса
.... + .... 20 ... + .... 40 ... + .... 60 ... + .... 80 ... + ....
76+ | 0 0,0%
72 | + 1 1.7%
1+ | 0 0,0%
0 | ********************************************** * - 55 98,2%
Распределение предполагаемых операций ввода-вывода для последовательного доступа к нижнему уровню с использованием 1 буфера
.... + .... 20 ... + .... 40 ... + .... 60 ... + .... 80 ... + ....
2+ | 0 0,0%
1 | + 1 1,7%
0 | ********************************************** * - 55 98,2%
Распределение количества страниц с промежуточным уровнем SR8
.... + .... 20 ... + .... 40 ... + .... 60 ... + .... 80 ... + ....
1+ | 0 0,0%
0 | ********************************************** ** 56 100,0%
Распределение минимального количества страниц с промежуточным уровнем SR8
.... + .... 20 ... + .... 40 ... + .... 60 ... + .... 80 ... + ....
1+ | 0 0,0%
0 | ********************************************** ** 56 100,0%
Распределение% смещенных промежуточных уровней SR8
.... + .... 20 ... + .... 40 ... + .... 60 ... + .... 80 ... + ....
1+ | 0 0,0%
0 | ********************************************** ** 56 100,0%
Распределение количества страниц с нижним уровнем SR8
.... + .... 20 ... + .... 40 ... + .... 60 ... + .... 80 ... + ....
2+ | 0 0,0%
1 | + 1 1,7%
0 | ********************************************** * - 55 98,2%
Распределение минимального количества страниц с нижним уровнем SR8
.... + .... 20 ... + .... 40 ... + .... 60 ... + .... 80 ... + ....
2+ | 0 0,0%
1 | + 1 1,7%
0 | ********************************************** * - 55 98,2%
Распределение% смещенных нижних уровней SR8
.... + .... 20 ... + .... 40 ... + .... 60 ... + .... 80 ... + ....
1+ | 0 0,0%
0 | ********************************************** ** 56 100,0%
Статус = 0 SQLSTATE = 00000
Печать сводного отчета REFERENCING ROWID индекса
В следующем отчете показано использование параметра REFERENCING ROWID для запроса печати вхождения индекса, содержащего идентификатор строки, ссылающейся на строку, идентифицированную X’013 ’.
УКАЗАТЕЛЬ ПЕЧАТИ "COV-IDX-SET" СЕГМЕНТ VLDBSPG1
ТАБЛИЦА SQLSPG.COVERAGE
ССЫЛКА НА ROWID X'013
'РЕЗЮМЕ;
Название набора: COV-IDX-SET
IBC 70 Рабочий объем 0
Вариант сортировки НЕ СОРТИРОВКА Длина ключа Н / Д
Дубликаты ПЕРВОЕ сжатие Нет
ВЛАДЕЛЕЦ: SR7
ОБЛАСТЬ VLDBSPG1.COVE-AREA Низкая страница (SUB- 80106
Размер страницы 4276 Высокая ПЛОЩАДЬ страницы) 80150
Группа страниц 5 записей на странице 255
УЧАСТНИК: ПОКРЫТИЕ Установить членство Необязательно Автоматически
Расположен индекс VIA Нет привязанного индекса
ОБЛАСТЬ VLDBSPG1.COVE-AREA Низкая страница (SUB- 80106
Размер страницы 4276 Высокая ПЛОЩАДЬ страницы) 80150
Группа страниц 5 записей на странице 255 OWNER X'013 'на странице 80130
Верхний уровень SR8 на странице 80130 использование 5.7%
Итоги появления индекса
Кол-во участников 74
Кол-во уровней 1 1 Минимум
Размер наибольшего SR8 316
Количество SR8s 2 2 Минимум
Количество страниц с SR8s 1 1 Минимум
Кол-во смещенных SR8 0 0.0%
Количество используемых записей 74 52,8%
Кол-во детей-сирот 0 0,0%
Общий размер всех SR8 368 Количество буферов по сравнению с предполагаемыми операциями ввода-вывода для последовательного доступа к нижнему уровню
------------- -------------
1–20 1
Статус = 0 SQLSTATE = 00000 Отчет Описание вывода
-
Часть 1 - Заголовок
Заголовок отчета содержит общую информацию об определении индекса, записи владельца индекса или таблице SQL, а также записи элемента индекса или таблице SQL. -
Часть 2 - Подробная информация о каждом появлении индекса
Подробный отчет о данных времени выполнения индекса для каждого экземпляра индекса всегда выводится для индекса, принадлежащего системе. Для индекса, принадлежащего пользователю, он выводится только при явном запросе с использованием SUMMARY DETAILED. В отчете содержится следующее: DBKEY экземпляра записи владельца индекса и номер его страницы.
Номер страницы первого (верхнего уровня) SR8. В идеале SR8 верхнего уровня должен находиться на той же странице, что и владелец индекса, за исключением индекса только с одним уровнем и ненулевым смещением индекса.
Количество записей, которые используются в SR8 верхнего уровня, выражается как процент использования максимального количества IBC, присвоенного индексу.
- На промежуточном и нижнем уровне (вывод, только если вхождение индекса имеет более одного уровня):
Число SR8 и его вычисленное минимальное значение
Число страниц с SR8 и его вычисленное минимальное значение
Количество перемещенных SR8 и в процентах от SR8
Количество используемых записей и в процентах от доступных записей
Количество сирот и процент использованных записей
Общий размер всех SR8
- Всего вхождений индекса:
Количество уровней в индексе и его вычисленное минимальное значение
Количество элементов в индексе
Размер самого большого SR8
Количество SR8 и его вычисленное минимальное значение
Количество страниц с SR8 и его вычисленное минимальное значение
Количество перемещенных SR8 и в процентах от SR8
Количество используемых записей и в процентах от доступных записей
Количество сирот и процент использованных записей
Общий размер всех SR8
Расчетное количество операций ввода-вывода в сравнении с количеством буферов базы данных для последовательного доступа нижнего уровня указывает на физическую «последовательность» индекса.В идеале количество входов / выходов не должно изменяться в зависимости от количества буферов и должно быть равно количеству страниц с SR8 нижнего уровня.
Смещенный SR8 - это нижний уровень SR8, расположенный в пределах смещения индекса, или не нижний уровень SR8, расположенный вне смещения индекса. Расчетное минимальное значение получается путем использования текущего количества записей в индексе, заполняя SR8 до 100 %, используя текущее значение INDEX BLOCK CONTAINS для индекса и предполагая, что все пространство на странице базы данных доступно для хранения владельца индекса и связанных SR8. Часть 3 - Обзор индекса и диаграммы распределения для индекса, принадлежащего пользователю
- Обзор индекса Обзор индекса предоставляет следующую информацию:
Количество появлений владельцев
Количество пустых владельцев и в процентах случаев появления владельцев
Количество перемещенных (не на одной странице с владельцем) верхнего уровня SR8
Общее, среднее и максимальное значение количества SR8
Общее, среднее и максимальное значение вычисленного минимального количества SR8
Среднее и максимальное значение уровня индекса
Среднее и максимальное значение вычисленного минимального уровня
Среднее и максимальное значения вычисленного минимального количества страниц
Число вхождений индекса с сиротами
Число сирот: всего и в процентах от количество записей и наивысший плюс его владелец DBKey
Общий размер всех SR8
Размер наибольшего SR8
- Диаграммы распределения Диаграмма распределения показывает количество и процент вхождений индекса для определенного свойства как в числовом, так и в псевдографическом виде.Свойства, для которых выводится диаграмма распределения:
Уровень индекса
Минимальный уровень индекса
Число элементов SR8
Число элементов в вхождении индекса
Расчетное количество операций ввода-вывода с использованием 1 буфера для последовательный доступ к нижнему уровню
Количество страниц с SR8 промежуточного уровня
Минимальное количество страниц с SR8 промежуточного уровня
Процент смещенных промежуточных уровней SR8
Количество страниц с SR8 нижнего уровня
Минимальное количество страниц с нижним уровнем для SR8
Процент смещенного нижнего уровня для SR8
.PRINT INDEX, команда
.PRINT INDEX, команда .PRINT INDEX, команда
. Печатает отсортированные записи указателя. .PRINT
Команда INDEX печатает список сгенерированных слов и номеров страниц.
автор: .INDEX
команды. Индекс отсортирован в алфавитном порядке.
Формат
Эта команда вызывает .BEGIN PAGE
команда и изменяет настройки вкладки так, чтобы индекс был напечатан
в две колонки на странице. Обратите внимание, что все записи, начинающиеся с верхнего регистра
буква будет отсортирована перед всеми записями, начинающимися со строчной буквы.Индекс печатается в конце документа.
Связанные команды
.INDEX
Магазины
указанный текст в списке указателей.
Печать индекса
В следующем примере вставляются элементы указателя с помощью команды .INDEX, а затем выполняется компиляция указателя.
с помощью команды .PRINT INDEX:
001.ПОКАЗАТЕЛЬ
'Первичный буфер вывода' Буфер вывода '
002 .INDEX
'Построение команды'
003 Используется команда H
разместить фиксированный
004 строки на выходе
буфер.
005 .INDEX
'Команда H' Фиксированные строки '
006. НАЧАТЬ
СТР.
007 Используется команда A
скопировать параметр
008 из входного буфера
в выходной буфер.
009 .INDEX
'Команда A' Получение ввода '
010 .INDEX
'Выходной буфер'
011 .ПЕЧАТЬ
ИНДЕКС
ПЕЧАТЬ
Команда INDEX печатает индекс на новой странице в конце
документ. Записи печатаются в формате двух столбцов:
А
команда
2
Выход
буфер
1,2
Создание команды
1
Первичный
выходной буфер
1
Фиксированные струны
1
Получение
ввод
2
H
команда
1
. Авторское право © 2026 Es picture - Картинки top