%d1%81%d0%bb%d0%be%d0%b9 — со всех языков на все языки
Все языкиРусскийАнглийскийИспанский────────Айнский языкАканАлбанскийАлтайскийАрабскийАрагонскийАрмянскийАрумынскийАстурийскийАфрикаансБагобоБаскскийБашкирскийБелорусскийБолгарскийБурятскийВаллийскийВарайскийВенгерскийВепсскийВерхнелужицкийВьетнамскийГаитянскийГреческийГрузинскийГуараниГэльскийДатскийДолганскийДревнерусский языкИвритИдишИнгушскийИндонезийскийИнупиакИрландскийИсландскийИтальянскийЙорубаКазахскийКарачаевскийКаталанскийКвеньяКечуаКиргизскийКитайскийКлингонскийКомиКомиКорейскийКриКрымскотатарскийКумыкскийКурдскийКхмерскийЛатинскийЛатышскийЛингалаЛитовскийЛюксембургскийМайяМакедонскийМалайскийМаньчжурскийМаориМарийскийМикенскийМокшанскийМонгольскийНауатльНемецкийНидерландскийНогайскийНорвежскийОрокскийОсетинскийОсманскийПалиПапьяментоПенджабскийПерсидскийПольскийПортугальскийРумынский, МолдавскийСанскритСеверносаамскийСербскийСефардскийСилезскийСловацкийСловенскийСуахилиТагальскийТаджикскийТайскийТатарскийТвиТибетскийТофаларскийТувинскийТурецкийТуркменскийУдмурдскийУзбекскийУйгурскийУкраинскийУрдуУрумскийФарерскийФинскийФранцузскийХиндиХорватскийЦерковнославянский (Старославянский)ЧеркесскийЧерокиЧеченскийЧешскийЧувашскийШайенскогоШведскийШорскийШумерскийЭвенкийскийЭльзасскийЭрзянскийЭсперантоЭстонскийЮпийскийЯкутскийЯпонский
Все языкиРусскийАнглийскийИспанский────────АймараАйнский языкАлбанскийАлтайскийАрабскийАрмянскийАфрикаансБаскскийБашкирскийБелорусскийБолгарскийВенгерскийВепсскийВодскийВьетнамскийГаитянскийГалисийскийГреческийГрузинскийДатскийДревнерусский языкИвритИдишИжорскийИнгушскийИндонезийскийИрландскийИсландскийИтальянскийЙорубаКазахскийКарачаевскийКаталанскийКвеньяКечуаКитайскийКлингонскийКорейскийКрымскотатарскийКумыкскийКурдскийКхмерскийЛатинскийЛатышскийЛингалаЛитовскийЛожбанМайяМакедонскийМалайскийМальтийскийМаориМарийскийМокшанскийМонгольскийНемецкийНидерландскийНорвежскийОсетинскийПалиПапьяментоПенджабскийПерсидскийПольскийПортугальскийПуштуРумынский, МолдавскийСербскийСловацкийСловенскийСуахилиТагальскийТаджикскийТайскийТамильскийТатарскийТурецкийТуркменскийУдмурдскийУзбекскийУйгурскийУкраинскийУрдуУрумскийФарерскийФинскийФранцузскийХиндиХорватскийЦерковнославянский (Старославянский)ЧаморроЧерокиЧеченскийЧешскийЧувашскийШведскийШорскийЭвенкийскийЭльзасскийЭрзянскийЭсперантоЭстонскийЯкутскийЯпонский
Не удается найти страницу | Autodesk Knowledge Network
(* {{l10n_strings. REQUIRED_FIELD}})
REQUIRED_FIELD}})
{{l10n_strings.ADD_COLLECTION_DESCRIPTION}}
{{l10n_strings.COLLECTION_DESCRIPTION}} {{addToCollection.description.length}}/500 {{l10n_strings.TAGS}} {{$item}} {{l10n_strings.PRODUCTS}} {{l10n_strings.DRAG_TEXT}} LANGUAGE}}
{{$select.selected.display}}
LANGUAGE}}
{{$select.selected.display}}{{article.content_lang.display}}
{{l10n_strings.AUTHOR}}Слои—Справка ArcGIS Online | Документация
В ArcGIS Online вы работаете с геоданными через слои.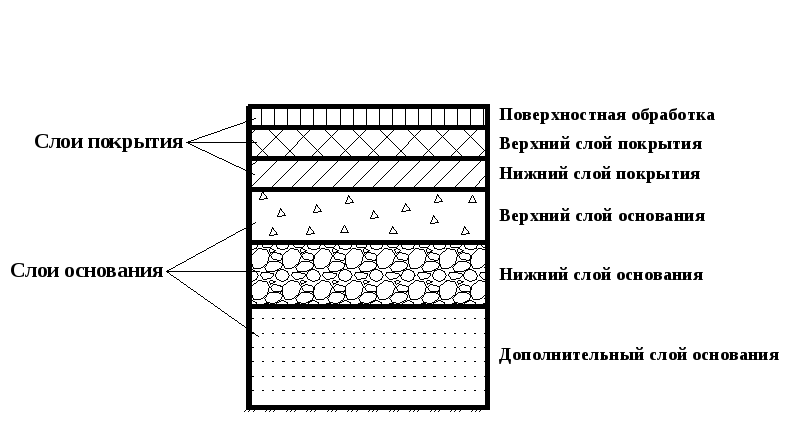 Слои, также называемые веб-слоями, это наборы географических данных, которые используются с целью создания карт и сцен; они также являются основой географического анализа. Например, слой зданий может отображать набор строений кампуса и содержит атрибуты, описывающие все характеристики соответствующего строения: тип, размер строения и многие другие потенциальные атрибуты. Другими примерами слоев могут также являться эпицентры землетрясений, исторические модели миграций, рельефы, 3D-здания, земельные участки и т.д.
Слои, также называемые веб-слоями, это наборы географических данных, которые используются с целью создания карт и сцен; они также являются основой географического анализа. Например, слой зданий может отображать набор строений кампуса и содержит атрибуты, описывающие все характеристики соответствующего строения: тип, размер строения и многие другие потенциальные атрибуты. Другими примерами слоев могут также являться эпицентры землетрясений, исторические модели миграций, рельефы, 3D-здания, земельные участки и т.д.
Источники данных
Основные типы отображаемых данных – это объекты и изображения. Различные типы слоев имеют различные особенности. Например, публикация данных из файла со значениями, разделенными запятыми, (файла CSV) приводит к созданию векторного слоя. С помощью векторных слоев вы можете создавать запросы к объектам и редактировать их в клиентских приложениях, а также управлять доступом к актуальным данным.
Данные слоев могут быть получены из различных источников. Некоторые источники данных являются родными для ArcGIS, например, размещенные сервисы ArcGIS Online и сервисы ArcGIS Server, другие являются файловыми источниками данных (например, файлы CSV и XLS), либо открытыми стандартами данных (например, KML и OGC).
Некоторые веб-слои – такие как векторные и слои изображений – предоставляют доступ к базовым данным, тогда как другие – слои листов и слои сцен – являются визуализацией данных, оптимизированной для конкретного использования. Вы можете размещать свои данные на ArcGIS Online или в базовых слоях, находящихся на ГИС-сервере. Публикация данных на ArcGIS Online позволяет размещать, или хранить, данные на ArcGIS Online, создавая слои, отображающие эти данные. Эти слои называются размещенными веб-слоями. При публикации данных как размещенного веб-слоя, слой содержит данные. ArcGIS Online может размещать векторные слои, слои листов, слои сцен и слои WFS.![]()
У вас также могут быть слои, которые ссылаются на данные, находящиеся на ГИС-сервере. Например, если вы зарегистрировали картографический сервис ArcGIS Server как элемент, то будет создан слой, который содержит ссылку на ваш сервис. Данные по-прежнему находятся в вашем картографическом сервисе и не копируются на ArcGIS Online.
Типы веб-слоев
Слои представляют собой географические объекты, такие как точки, линии, полигоны, изображения, рельеф поверхности, ячейки сетки или виртуально любые данные с поддержкой местоположения, такие как датчики погоды, дорожные условия, камеры безопасности, твиты. Тип слоя определяет, как пользователь может взаимодействовать с его данными. Например, у векторных слоев можно просматривать и запрашивать данные, чтобы узнать об атрибутах объектов. Вы также можете редактировать данные, представленные векторным слоем. В случае слоев листов, можно только просматривать листы с изображениями объектов.
На портале ArcGIS веб-слои делятся по типу содержащихся в них данных, например, слои высот, объектов или изображений. Это помогает объединить все, что отображается на карте, в единое целое. Значки также позволяют обозначать типы данных на слое. Источник веб-слоев описывается на странице описания элемента.
Это помогает объединить все, что отображается на карте, в единое целое. Значки также позволяют обозначать типы данных на слое. Источник веб-слоев описывается на странице описания элемента.
Следующие типы веб-слоев могут быть опубликованы или добавлены на портал ArcGIS в качестве его элемента:
- Слой изображений карты – коллекция карт, картографически основанная на векторных данных. К векторным данным относятся точки, линии и полигоны. Слои изображений карты являются динамически отображаемыми листами изображений.
- Слой изображений – коллекция карт, картографически основанная на растровых данных. Растровые данные представляют собой сетку ячеек, обычно используемую для хранения изображений и другой информации, полученной от сенсоров дистанционного зондирования. Слои изображений могут отображаться динамически или как заранее подготовленные изображения кэшированной карты.
- Слой листов – набор доступных в сети листов, размещенных на сервере. Тайловые слои могут содержать подготовленные растровые листы карты или векторные листы.
- Слой высот – группа готовых кэшированных листов изображений в формате Limited Error Raster Compression (LERC). LERC – это формат сжатия одноканальных данных или данных высот. Слои высот подходят для отображения рельефа в сценах глобального и локального масштабов.
- Векторный слой—это группа схожих географических объектов, например, здания, участки, города, дороги или эпицентры землетрясений. Объекты могут быть точками, линиями или полигонами. Векторные слои лучше всего использовать для визуализации данных поверх базовых карт. Вы можете задавать свойства для векторных слоев, такие как стиль, прозрачность, диапазон видимости, интервал обновления и надписи, которые управляют внешним видом отображаемого слоя на карте. Используя векторный слой, вы можете просматривать, редактировать, анализировать объекты и выполнять запросы к объектам и их атрибутам.
 Содержание некоторых векторных слоев можно загрузить. Потоковые объекты могут быть источниками слоев объектов. Коллекции объектов – это другой тип векторного слоя.
Содержание некоторых векторных слоев можно загрузить. Потоковые объекты могут быть источниками слоев объектов. Коллекции объектов – это другой тип векторного слоя. - Слой сцены – группа 3D объектов и z-значений (значений высот). Доступны слои сцены следующих типов: точка, 3D объект, интегрированная модель mesh, облако точек и строение.
- Таблица – набор строк и столбцов, в котором каждая строка, или запись, представляет собой отдельный объект или событие – например клиент или банковский перевод – а каждый столбец, или поле, описывает определенный атрибут объекта, например, имя или дату. Таблицы могут содержать сведения о местоположении, например адреса, но это необязательно. Например, у вас может быть простой список имен и зарплат сотрудников. Таблицы не показываются на карте, даже если в них есть данные о местоположении.
Но слои – это не только данные. Слой представляет данные и способ их визуализации. К визуализации относятся символы и цвета, которые используются для отображения данных, равно как и всплывающие окнапараметры, прозрачность, фильтры и другие свойства слоя.
Копии слоев
Чтобы визуализировать или представить данные слоя несколькими способами, вы можете создать копию слоя. Для большинства типов слоев данные не копируются. Рассматривайте копию слоя как свою собственную копию настроек визуализации, которую вы можете изменить, чтобы представить данные так, как вам нужно.
Подробнее см. в разделе Копирование и сохранение слоев.
Как используются слои
Ссылка на одни и те же данные может использоваться различными слоями, что позволяет создавать различные представления и типы слоев на основе одних и тех же данных. Один и тот же слой может использоваться во множестве веб-карт и веб-сцен, дополнительная настройка слоя не требуется.
Получение исходных данных. | |
Публикация данных как слоев. | |
Создание карт и сцен, содержащих слои. | |
Создание приложений, содержащих карты и сцены. |
Слои — это основные составляющие веб-карт и веб-сцен. Каждая карта и сцена содержит базовую карту и может содержать другие слои, которые отображаются поверх базовой карты. Слои базовых карт обычно используются только для просмотра и создания контекста, обычно это слои листов, слои изображений карты или слои изображений. Слои, отображаемые поверх базовой карты, могут состоять из пространственных объектов или изображений, и называются рабочими слоями. Рабочие слои – это слои, с которыми вы взаимодействуете. Таким взаимодействием может быть просмотр атрибутивной информации, редактирование объектов или выполнение анализа.
С картами, сценами и слоями можно работать как с элементами в ArcGIS Online. Эти элементы отображаются на странице ресурсов, ими можно поделиться с другими людьми, и они доступны для поиска в ArcGIS Online. Хотя большинство слоев доступны на ArcGIS Online как элементы, некоторые из них недоступны как элементы; такие слои доступны только в содержащей их веб-карте. Например, вы можете добавить слой GeoRSS из интернета на карту, но вы не можете добавить слой GeoRSS в качестве элемента. Аналогично, можно добавить файл CSV непосредственно на карту. В этом случае векторный слой, созданный при добавлении файла CSV, доступен только на карте, но не в виде отдельного элемента.
Для получения рекомендаций о том, когда создавать различные типы слоев, см. Рекомендации для публикации слоев. Рекомендации о том, какие типы слоев использовать на ваших картах, см. Рекомендации по созданию карт .
Рекомендации для публикации слоев. Рекомендации о том, какие типы слоев использовать на ваших картах, см. Рекомендации по созданию карт .
Отзыв по этому разделу?
определение «FTL»: Слой Flash-перевод — Flash Translation Layer
Что означает FTL? FTL означает Слой Flash-перевод. Если вы посещаете нашу неанглоязычную версию и хотите увидеть английскую версию Слой Flash-перевод, пожалуйста, прокрутите вниз, и вы увидите значение Слой Flash-перевод на английском языке. Имейте в виду, что аббревиатива FTL широко используется в таких отраслях, как банковское дело, вычислительная техника, образование, финансы, правительство и здравоохранение. В дополнение к FTL, Слой Flash-перевод может быть коротким для других сокращений.
FTL = Слой Flash-перевод
Ищете общее определение FTL? FTL означает Слой Flash-перевод. Мы с гордостью перечисляем аббревиатуру FTL в самую большую базу данных сокращений и сокращений.
Значения FTL на английском языке
Как уже упоминалось выше, FTL используется в качестве аббревиатуры в текстовых сообщениях для представления Слой Flash-перевод. Эта страница все о аббревиатуре FTL и его значения, как Слой Flash-перевод. Пожалуйста, обратите внимание, что Слой Flash-перевод не является единственным смыслом FTL. Там может быть более чем одно определение FTL, так что проверить его на наш словарь для всех значений FTL один за одним.Определение в английском языке: Flash Translation Layer
Другие значения FTL
Кроме Слой Flash-перевод, FTL имеет другие значения. Они перечислены слева ниже. Пожалуйста, прокрутите вниз и нажмите, чтобы увидеть каждый из них. Для всех значений FTL, пожалуйста, нажмите кнопку «Больше». Если вы посещаете нашу английскую версию и хотите увидеть определения Слой Flash-перевод на других языках, пожалуйста, нажмите на языковое меню справа. Вы увидите значения Слой Flash-перевод во многих других языках, таких как арабский, датский, голландский, хинди, Япония, корейский, греческий, итальянский, вьетнамский и т.д.
Если вы посещаете нашу английскую версию и хотите увидеть определения Слой Flash-перевод на других языках, пожалуйста, нажмите на языковое меню справа. Вы увидите значения Слой Flash-перевод во многих других языках, таких как арабский, датский, голландский, хинди, Япония, корейский, греческий, итальянский, вьетнамский и т.д.Знакомство с трансформерами. Часть 2 / Хабр
Публикуем вторую часть материала о трансформерах. В первой части речь шла о теоретических основах трансформеров, были показаны примеры их реализации с использованием PyTorch. Здесь поговорим о том, какое место слои внутреннего внимания занимают в нейросетевых архитектурах, и о том, как создают трансформеры, ориентированные на решение различных задач.
Разработка трансформеров
Трансформер — это не только слой внутреннего внимания. Это — архитектура машинного обучения. На самом деле, не вполне ясен вопрос о том, что можно, а что нельзя назвать «трансформером», но мы тут будем использовать следующее определение:
Трансформер — это любая архитектура, спроектированная в расчёте на обработку связанных наборов неких сущностей, таких, как токены в последовательности пикселей изображения, где эти сущности взаимодействуют только посредством механизма внутреннего внимания.

Как и в случае с другими механизмами, применяемыми в машинном обучении, вроде свёрточных слоёв, сформировался более или менее стандартный подход к включению механизмов внутреннего внимания в состав более крупных нейронных сетей. Поэтому мы начнём с оформления механизма внутреннего внимания в виде самостоятельного блока, который можно будет использовать в различных сетях.
Блок трансформера
Получается, что в этом блоке, последовательно, входные данные проходят через следующие слои:
Слой внутреннего внимания.
Слой нормализации.
Слой прямого распространения (по одному многослойному перцептрону на каждый вектор).
Ещё один слой нормализации.
Линии, обходящие слои внутреннего внимания и прямого распространения, расположенные до слоёв нормализации — это остаточные соединения. Порядок компонентов в блоке трансформера не фиксирован. Важные моменты здесь — комбинирование слоя внутреннего внимания с локальным слоем прямого распространения, наличие слоёв нормализации и остаточных соединений.
Порядок компонентов в блоке трансформера не фиксирован. Важные моменты здесь — комбинирование слоя внутреннего внимания с локальным слоем прямого распространения, наличие слоёв нормализации и остаточных соединений.
Применение слоёв нормализации и остаточных соединений — это стандартные приёмы, используемые для увеличения скорости и точности обучения глубоких нейронных сетей. Нормализация применяется только к измерению эмбеддинга.
Вот как выглядит блок трансформера в PyTorch:
class TransformerBlock(nn.Module):
def __init__(self, k, heads):
super().__init__()
self.attention = SelfAttention(k, heads=heads)
self.norm1 = nn.LayerNorm(k)
self.norm2 = nn.LayerNorm(k)
self.ff = nn.Sequential(
nn.Linear(k, 4 * k),
nn.ReLU(),
nn.Linear(4 * k, k))
def forward(self, x):
attended = self.attention(x)
x = self.norm1(attended + x)
fedforward = self.ff(x)
return self.norm2(fedforward + x)Мы, без особых на то причин, решили сделать скрытый слой прямого распространения в 4 раза больше, чем слои входов и выходов.![]() Тут вполне могут подойти и меньшие значения, это поможет сэкономить память, но этот слой должен быть больше входных и выходных слоёв.
Тут вполне могут подойти и меньшие значения, это поможет сэкономить память, но этот слой должен быть больше входных и выходных слоёв.
Трансформеры и решение задач классификации
Простейший трансформер, который мы можем создать — это классификатор последовательностей. Мы воспользуемся набором данных, представляющим собой классификацию тональности текстов с IMDb. А именно, элементы этого набора представлены обзорами фильмов, разбитыми на последовательности токенов (слов). Обзорам назначается одна из двух меток классификации: positive и negative. Первая соответствует позитивным отзывам, вторая — негативным.
Сердцем этой архитектуры является довольно-таки простая система, представляющая собой длинную цепочку блоков трансформера. Всё, что нам остаётся сделать для создания работающего классификатора — разобраться в том, как передавать системе входные последовательности, и в том, как преобразовывать итоговые выходные данные в результат классификации.
Полный код этого эксперимента можно найти здесь. В этом материале мы не касаемся вопросов первичной обработки данных. Проанализировав код, можно узнать о том, как данные загружаются и подготавливаются к дальнейшему использованию.
Выход: результат классификации
Чаще всего классификаторы последовательностей создают из слоёв, выполняющих преобразование последовательности в последовательность. Делают это, применяя операцию GAP (Global Average Pooling, глобальный усредняющий пуллинг) к итоговой выходной последовательности и отображая результат на классификационный вектор, обрабатываемый с помощью функции Softmax.
Общая схема простого трансформера, используемого для классификации последовательностей. Выходная последовательность усредняется для получения одного вектора, представляющего всю последовательность. Этот вектор проецируется на вектор, содержащий по одному элементу на каждый класс, и обрабатывается функцией Softmax для получения вероятностейВход: использование позиционных эмбеддингов или кодировок
Мы уже говорили о принципах, на которых основаны эмбеддинг-слои. Именно их мы и будем использовать для представления слов.
Именно их мы и будем использовать для представления слов.
Но, о чём мы тоже уже говорили, мы накладываем друг на друга слои, эквивариантные к перестановкам, а итоговый глобальный усредняющий пуллинг инвариантен к перестановкам. В результате вся сеть инвариантна к перестановкам. Проще говоря: если перемешать слова в предложении — результат классификации будет таким же, как и для исходного приложения, вне зависимости от того, к нахождению каких весов привело обучение сети. Очевидно то, что нам хотелось бы, чтобы наша современнейшая языковая модель хотя бы немного реагировала на изменение порядка слов, поэтому она нуждается в доработке.
Для этого можно применить довольно простое решение: создаётся ещё один вектор той же длины, представляющий позицию слова в текущем предложении, который добавляется к эмбеддингу слов. Сделать это можно двумя способами.
Первый — это использование позиционных эмбеддингов. Мы просто включаем в состав эмбеддинга позиции — так же, как делали со словами. Например, мы создавали векторы эмбеддинга и , а теперь будем создавать ещё и векторы и . И так — вплоть до значений, соответствующих ожидаемой длине последовательности. Минус этого подхода заключается в том, что в процессе обучения модели нам нужно будет обработать последовательности всех длин, встречающихся в наборе, иначе модель не научится тому, как воспринимать соответствующие позиционные эмбеддинги. А сильные стороны этого решения в том, что работает оно очень хорошо, и в том, что его легко реализовать.
Например, мы создавали векторы эмбеддинга и , а теперь будем создавать ещё и векторы и . И так — вплоть до значений, соответствующих ожидаемой длине последовательности. Минус этого подхода заключается в том, что в процессе обучения модели нам нужно будет обработать последовательности всех длин, встречающихся в наборе, иначе модель не научится тому, как воспринимать соответствующие позиционные эмбеддинги. А сильные стороны этого решения в том, что работает оно очень хорошо, и в том, что его легко реализовать.
Второй — это использование позиционных кодировок. Работают они так же, как и позиционные эмбеддинги, за исключением того, что модели не предлагается, в процессе обучения, обрабатывать позиционные вектора. Мы всего лишь выбираем некую функцию f: , применяемую для сопоставления позиций с векторами, содержащими реальные значения, и позволяем сети разобраться с тем, как интерпретировать эти кодировки. Плюс тут в том, что, если функция выбрана удачно, у сети должна появиться возможность работать с последовательностями, которые длиннее, чем те, которые предлагались ей в процессе обучения (модель вряд ли будет показывать на них хорошие результаты, но, как минимум, можно будет её на таких последовательностях проверить).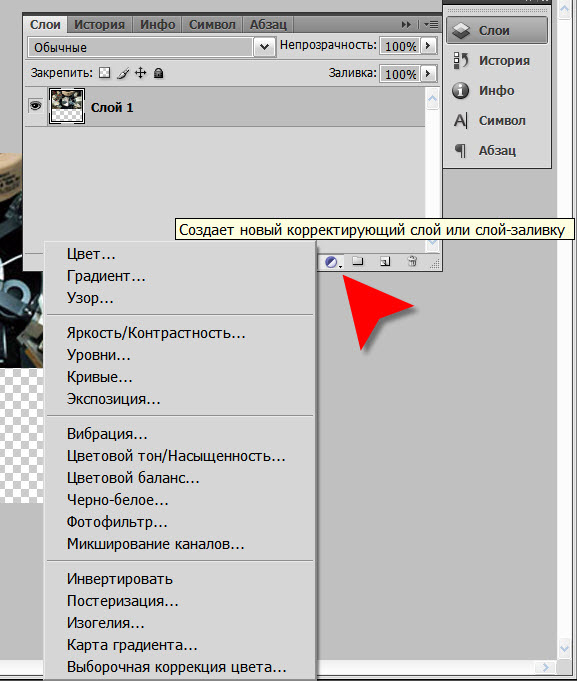 А минус этого подхода в том, что выбор кодировочной функции влияет на сложный гиперпараметр, что немного усложняет реализацию системы.
А минус этого подхода в том, что выбор кодировочной функции влияет на сложный гиперпараметр, что немного усложняет реализацию системы.
Мы, ради простоты, воспользуемся в нашей реализации трансформера-классификатора позиционными эмбеддингами.
Реализация трансформера-классификатора в PyTorch
Вот полноценный трансформер, предназначенный для классификации текстов, реализованный средствами PyTorch:
class Transformer(nn.Module):
def __init__(self, k, heads, depth, seq_length, num_tokens, num_classes):
super().__init__()
self.num_tokens = num_tokens
self.token_emb = nn.Embedding(num_tokens, k)
self.pos_emb = nn.Embedding(seq_length, k)
# Последовательность блоков трансформера, на которую
# возлагается обязанность решения сложных задач
tblocks = []
for i in range(depth):
tblocks.append(TransformerBlock(k=k, heads=heads))
self.tblocks = nn.Sequential(*tblocks)
# Настраиваем соответствие итоговой выходной последовательности ненормализованным значениям, получаемым для различных классов
self. toprobs = nn.Linear(k, num_classes)
def forward(self, x):
"""
:param x: A (b, t) тензор целочисленных значений, представляющий
слова (в некоем заранее заданном словаре).
:return: A (b, c) тензор логарифмических вероятностей по
классам (где c - это количество классов).
"""
# генерируем эмбеддинги токенов
tokens = self.token_emb(x)
b, t, k = tokens.size()
# генерируем позиционные эмбеддинги
positions = torch.arange(t)
positions = self.pos_emb(positions)[None, :, :].expand(b, t, k)
x = tokens + positions
x = self.tblocks(x)
# Выполняем операцию усредняющего пуллинга по t измерениям и проецируем
# на вероятности, соответствующие классам
x = self.toprobs(x.mean(dim=1))
return F.log_softmax(x, dim=1)
toprobs = nn.Linear(k, num_classes)
def forward(self, x):
"""
:param x: A (b, t) тензор целочисленных значений, представляющий
слова (в некоем заранее заданном словаре).
:return: A (b, c) тензор логарифмических вероятностей по
классам (где c - это количество классов).
"""
# генерируем эмбеддинги токенов
tokens = self.token_emb(x)
b, t, k = tokens.size()
# генерируем позиционные эмбеддинги
positions = torch.arange(t)
positions = self.pos_emb(positions)[None, :, :].expand(b, t, k)
x = tokens + positions
x = self.tblocks(x)
# Выполняем операцию усредняющего пуллинга по t измерениям и проецируем
# на вероятности, соответствующие классам
x = self.toprobs(x.mean(dim=1))
return F.log_softmax(x, dim=1)
Этот трансформер, при глубине 6 и при максимальной длине последовательности 512, достигает точности классификации текстов около 85%, что сопоставимо с результатами RNN-моделей (моделей, основанных на рекуррентных нейронных сетях, Recurrent Neural Network), при условии, что обучение трансформера идёт гораздо быстрее. Для того чтобы довести результаты трансформера до уровня, приближающегося к человеческому, нужно обучать гораздо более глубокую модель на гораздо большем объёме данных. Позже мы поговорим о том, как это сделать.
Для того чтобы довести результаты трансформера до уровня, приближающегося к человеческому, нужно обучать гораздо более глубокую модель на гораздо большем объёме данных. Позже мы поговорим о том, как это сделать.
Трансформеры, генерирующие тексты
Следующий приём, который мы собираемся испытать, заключается в использовании авторегрессионной модели. Мы научим трансформер, работающий на уровне отдельного символа, предсказывать следующий символ последовательности. Обучение такого трансформера — это просто (и эта методика появилась задолго до появления трансформеров). Мы даём модели, выполняющей преобразование последовательностей в последовательности, последовательность символов, и предлагаем ей предсказать, для каждой позиции последовательности, следующий символ. Другими словами, целевая выходная последовательность — это та же последовательность, сдвинутая влево на один символ.
Общая схема трансформера, генерирующего текстыЕсли бы мы применяли RNN, то сейчас у нас уже было бы всё, что нужно, так как такие сети не могут заглядывать в «будущее» входных последовательностей: выход i зависит только от входов от 0 до i. А в случае с трансформерами выход зависит от всей входной последовательности, в результате предсказание следующего символа становится до смешного простым: достаточно взять его из входной последовательности.
А в случае с трансформерами выход зависит от всей входной последовательности, в результате предсказание следующего символа становится до смешного простым: достаточно взять его из входной последовательности.
Для того чтобы использовать механизм внутреннего внимания в роли авторегрессионной модели, нужно сделать так, чтобы модель не смогла бы заглянуть в «будущее». Делается это путём применения маски к матрице скалярных произведений, до применения функции Softmax. Эта маска отключает все элементы, находящиеся выше диагонали матрицы.
Маскирование матрицы механизма внутреннего внимания позволяет обеспечить то, что элементы будут реагировать только на входные элементы, которые идут в последовательности до них. Обратите внимание на то, что символ умножения применяется здесь не в обычном для него смысле: мы, на самом деле, устанавливаем замаскированные элементы (белые квадраты) в ∞.Так как нам нужно, чтобы соответствующие элементы, после применения функции Softmax, стали бы нулями, мы устанавливаем их в ∞. Вот как это выглядит в PyTorch:
dot = torch.bmm(queries, keys.transpose(1, 2))
indices = torch.triu_indices(t, t, offset=1)
dot[:, indices[0], indices[1]] = float('-inf')
dot = F.softmax(dot, dim=2)После того, как мы таким вот образом ограничили возможности модуля внутреннего внимания, модель больше не может «подглядывать» во входную последовательность.
Мы обучаем модель на стандартном наборе данных enwik8 (он взят из материалов соревнования Маркуса Хаттера по сжатию данных), который содержит 108 символов текста Википедии (включая разметку). В процессе обучения мы генерируем пакеты текстов, случайным образом выбирая подпоследовательности из данных.
Мы обучаем модель на последовательностях длиной 256, используя систему из 12 блоков трансформера и 256 измерений эмбеддингов. После примерно 24 часов обучения модели на видеокарте RTX 2080Ti (около 170 тысяч пакетов длиной 32) мы позволили модели сгенерировать текст на основе начального фрагмента длиной 256 символов. Для генерирования каждого символа мы передавали модели 256 предыдущих символов, и смотрели на то, что она предложит в качестве следующего символа (последний выходной вектор). При выборе символа использовался метод «температурного сэмплирования» с показателем 0,5. После выбора очередного символа мы переходили к следующему символу.
Модель выдала следующий текст (полужирным выделен начальный фрагмент):
1228X Human & Rousseau. Because many of his stories were originally published in long-forgotten magazines and journals, there are a number of [[anthology|anthologies]] by different collators each containing a different selection. His original books have been considered an anthologie in the [[Middle Ages]], and were likely to be one of the most common in the [[Indian Ocean]] in the [[1st century]]. As a result of his death, the Bible was recognised as a counter-attack by the [[Gospel of Matthew]] (1177-1133), and the [[Saxony|Saxons]] of the [[Isle of Matthew]] (1100-1138), the third was a topic of the [[Saxony|Saxon]] throne, and the [[Roman Empire|Roman]] troops of [[Antiochia]] (1145-1148). The [[Roman Empire|Romans]] resigned in [[1148]] and [[1148]] began to collapse. The [[Saxony|Saxons]] of the [[Battle of Valasander]] reported the y
Обратите внимание на то, что здесь правильно применяются синтаксические конструкции, используемые в Википедии для оформления ссылок, на то, что в ссылках приведены адекватные тексты. А самое важное то, что этот текст обладает хоть какой-то тематической согласованностью. А именно, сгенерированный текст придерживается тем, связанных с Библией и Римской империей, в нём, в разных местах, используются смежные термины. Конечно, нашей модели далеко до более продвинутых систем, вроде GPT-2, но даже здесь видны очевидные преимущества трансформеров перед схожими RNN-моделями: более быстрое обучение (сопоставимую RNN-модель пришлось бы обучать много дней) и лучшая долговременная согласованность.
Если вам интересно — что это за «Battle of Valasander», то знайте, что эту битву, похоже, сеть выдумала сама.
Модель, в описываемом состоянии, обеспечила уровень сжатия, соответствующий 1,343 бита на байт на проверочном наборе, что не так уж и сильно отличается от передовых 0,93 бита на байт, достигнутых моделью GPT-2 (подробнее о ней мы поговорим далее).
Особенности проектирования трансформеров
Для того чтобы понять то, почему трансформеры делают именно такими, полезно разобраться с базовыми факторами, влияющими на процесс их проектирования. Главная цель трансформеров заключалась в решении проблем архитектуры, которая до их появления считалась самой современной. Речь идёт о RNN. Обычно — это LSTM (Long Short-Term Memory, длинная цепь элементов краткосрочной памяти) или GRU (Gated Recurrent Units, управляемые рекуррентные блоки). Вот схема развёрнутой рекуррентной нейронной сети.
Схема рекуррентной нейронной сетиСерьёзная слабость этой архитектуры заключается в рекуррентных соединениях (показаны синими линиями). Хотя это и позволяет информации распространяться по последовательности, это ещё и означает, что мы не можем вычислить значение, выдаваемое ячейкой на временном шаге до тех пор, пока не вычислим её значение на шаге – 1. Сравним это с одномерной свёрткой.
Одномерная свёрткаВ этой модели все выходные векторы могут быть вычислены параллельно. Это делает свёрточные сети гораздо производительнее сетей с рекуррентными соединениями. Минус таких сетей, однако, заключается в том, что они сильно ограничены в моделировании долговременных зависимостей. В одном свёрточном слое взаимодействовать друг с другом могут только слова, расстояние между которыми не превышает размеров свёрточного ядра. Для обеспечения обработки зависимостей, расположенным на больших расстояниях, нужно наложить друг на друга несколько свёрточных слоёв.
Трансформеры — это попытка взять лучшее из двух миров. Они могут моделировать зависимости на всём диапазоне входной последовательности так же легко, как это делается для слов, находящихся рядом друг с другом (на самом деле, без использования позиционных векторов, они даже не увидят разницы между такими зависимостями). Но при этом в них не используются рекуррентные соединения, в результате всю модель можно весьма эффективно обсчитать, пользуясь тем же подходом, который применяется при работе с сетями прямого распространения.
Остальные особенности архитектуры трансформеров основаны, по большей части, на единственном соображении. Это — глубина сети. В основе архитектур большинства трансформеров лежит желание обучить большую «стопку» блоков трансформера. Заметьте, например, что в трансформере есть всего два места, где производятся нелинейные преобразования данных. Это — место, где в блоке внутреннего внимания применяется функция Softmax, и место, где применяется ReLU (Rectified Linear Unit, выпрямленная линейная функция активации) в слое прямого распространения. Вся остальная модель полностью состоит из линейных трансформаций, что не мешает применению градиента.
Полагаю, что слой нормализации тоже отличается нелинейностью, но это — та самая нелинейность, которая, на самом деле, способствует стабильности градиента при его обратном распространении по сети.
Продолжение следует…
О, а приходите к нам работать? 😏Мы в wunderfund.io занимаемся высокочастотной алготорговлей с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
Присоединяйтесь к нашей команде.
Как слой жира на поддоне для картофеля фри в Макдоналдсе напугал зрителей
Ролик из ресторана «Макдоналдс» с поддоном для картошки фри, полным жира и соли, напугал многих зрителей. После просмотра кадров некоторые фанаты фастфуда пожалели о своей любви к быстрой еде и, кажется, впервые задумались о своём здоровье.
В вирусном видео австралийский тиктокер с ником maccaschick показал процесс чистки поддона после приготовления картофеля фри в сети быстрого питания «Макдоналдс». В ролике сотрудник ресторана с помощью металлической лопатки соскоблил остатки соли, жира и картошки со дна лотка, в котором готовится фастфуд. В подписи к публикации автор намекнул — выбор некоторых покупателей, считающих блюдо «безопаснее» других позиций в меню, сложно назвать правильным.
— Я пытаюсь питаться правильно, поэтому возьму только картофель фри, — передаёт слова части клиентов тиктокер.
— Ты в этом уверен? — спрашивает автор видео.
Многих пользователей Сети напугал виральный ролик — любители жареного картофеля, кажется, не захотели знать, как им показалось, неприятные подробности его приготовления.
Мне не нужно было это видеть.
Как человеку, обожающему картофель фри, мне не понравилось это видео.
А кто-то после просмотра тиктока даже нашёл причину недомогания — как посчитали некоторые комментаторы, секрет плохого самочувствия кроется в съеденном накануне фастфуде.
Я только что съел картофель фри из «Макдоналдса» и теперь чувствую себя плохо.
Впрочем, блогер успокоил встревоженных зрителей, опубликовав ролик, в котором объяснил: соль и жир соскабливаются не с того места, где лежит сама картошка, а с поддона, куда ссыпаются отходы через фильтр.
Это всё остатки, прошедшие через фильтр, а не ваша еда, — подписал видео тиктокер.
Ранее Medialeaks рассказал, как черви в аппарате для газировки из «Макдоналдса» напугали многих комментаторов. После просмотра ролика некоторые зрители, кажется, навсегда отказались от походов в популярную сеть быстрого питания.
О том, как готовится «Биг Мак» и в чём изюминка «Филе-о-фиш», читайте в материале Medialeaks. Работник ресторана рассказал мини-секреты заведения.
Oxxxymiron – Чувствую (Feel) Lyrics
[Текст песни «Чувствую»][Припев]
Объясни, что я чувствую
Загляни в эту пустоту
Вышел в магазин, на свету стою
Просканируй мои сны, я вернусь во тьму
Чувствую, чувствую, чувствую, чувствую
Как определить: этот остов пуст
Или у меня внутри целый сгусток чувств?
[Куплет 1]
В этот раз я не шарю совсем
Но чувствую, что басс ощущает сосед
Чувствую, как текст набухает при всех
Будто свежий крест опускается в снег
Не чувствую себя бесчувственно стебя себя
Чую: ты вне себя, отсутствую, даже ебя
Цедя искусственности яд, в конвульсиях змея
Меж чувствами и чувственностью узкая стезя
Я так запутался в тенях, яму разрыв
До подсознанья, отрицая право на срыв
Я шарюсь впотьмах, усугубляю, сострив
Каюсь стремглав, улыбаюсь навзрыд, догорают костры
Чувства во мне сидят они пустоту населяют
По ту сторону стекла
Юркие существа, я лишь хрусткая скорлупа для них
Они — экстравагантная, шустрая толпа
А может я пуст, как в витрине рюкзак?
Внутри нет чувств, летит упаковка в мусор
Радость и грусть — знаменит арсенал иллюзий
А на свету спутанный исчезает узел
То в чувствах тону, то пусто в аду
Я — тот царь-самодур, Rosebud, Xanadu
Хошь сладкие сны? Каракум, курагу?
Арендуй тамаду, каррент муд — Барад Дур, ну-ка
Объясни, что я чувствую
Загляни в эту пустоту
Вышел в магазин, на свету стою
Просканируй мои сны, я вернусь во тьму
Чувствую, чувствую, чувствую, чувствую
Как определить: этот остов пуст
Или у меня внутри целый сгусток чувств?
[Куплет 2]
Представь: Гитлер поступил, картина маслом
На ней сестры Вачовски, братья Стругацкие, Питер
На фасадах гипсовые маски
Гигер — гиперреалист, а не фантаст
Не слиться душой мне с Иным в унисон
Снится Чужой, но с моим же лицом
Мнится любовь, но способен походу
Разве что смешивать соки с другим существом
Это лишь верхний слой
В нем ощущение:
Отчуждение, клиповое мышление
Эго шевелится ниже, как рак-отшельник
И ищет выход в зависимом поведении
Психика, будто оголенный провод
Слышу «ха-ха» — думаю, надо мною гогот
Прикинь: я не умею проживать эмоции
Лишь отсылать эмоджи навязанные японцами, блядь
Отправление — в один конец одноколейка
Ускоренье Ника Лэнда с откровеньем Ника Кейва
Поколение между эксцессом и аскезой
Быть местным — выбирать между протестом и отъездом
Если честно, Хьюстон, у меня по сути лишь одна проблема: чувства
Зови меня «викинг» за предчувствие конца
Зови меня «Weekend»: я не чувствую лица
Алло-алло, это Хьюстон, будь тебе, сука, пусто
Жизнь — это всегда очень грустно
Гнусно воткнуть исподтишка — нож
В руки вываливается кишка — ложь
Лжи психоаналитика — кровь
Слёзы — дерьмо
Всё, что захочешь, за деньги нытика
[Бридж]
Ночью нарезаю круги
Узнаешь — беги, я раню себя и других
И ради себя и других
Я всё копаю, никак не выкупая, чё там внутри, а-а
[Припев]
Объясни, что я чувствую
Загляни в эту пустоту
Вышел в магазин, на свету стою
Просканируй мои сны, я вернусь во тьму
Чувствую, чувствую, чувствую, чувствую
Как определить: этот остов пуст
Или у меня внутри целый сгусток чувств?
Flash Translation Layer — обзор
3.1 Архитектура
Современные операционные системы имеют тенденцию быть структурированными в отдельные, автономные уровни с небольшим межуровневым состоянием или совместным использованием данных. Системы хранения на основе флэш-памяти также используют многоуровневую архитектуру. На рис. 3 показаны основные уровни типичной системы хранения на основе флэш-памяти. По сравнению с традиционными системами хранения [23] драйвер уровня трансляции флэш-памяти (FTL) [14,51,54,59] и драйвер устройства технологии памяти (MTD) [67] являются двумя важными уровнями для хранения на основе флэш-памяти. системы.Драйвер MTD в основном обеспечивает три низкоуровневые операции, включая чтение, запись и стирание. Основываясь на функциональных возможностях низкого уровня, FTL отвечает за то, как обрабатывать определенные характеристики флеш-памяти. Задача драйвера FTL — предоставить файловым системам прозрачные службы для доступа к флеш-памяти как к блочному устройству, оптимизировать производительность с использованием наименьшего объема оперативной памяти и увеличить срок службы за счет использования техники выравнивания износа. Функциональные возможности FTL и MTD могут быть интегрированы в любую прошивку внутри устройства флэш-памяти (например,г. Disk on Module) или файловой системы (например, Memory StickTM) [38].
Рис. 3. Типовая флеш-память.
Рис. 3 описывает поток данных в типичной системе хранения на основе флэш-памяти. Приложения выдают запросы ввода-вывода, вызывая API файловой системы (например, fread / fwrite). Файловые системы обычно управляют емкостью хранилища как линейным массивом блоков фиксированного размера. Следовательно, доступ к файлу преобразуется файловой системой во многие запросы ввода-вывода на уровне блоков. Каждый запрос ввода-вывода на уровне блока содержит конкретный логический адрес блока (LBA) и длину блока данных.Запросы ввода-вывода на уровне блоков проходят через FTL и транслируются в определенные команды, предоставляемые флэш-памятью. Команды будут преобразованы в управляющие сигналы для доступа к необработанной флеш-памяти.
Типичный носитель флэш-памяти поддерживает чтение страницы, запись страницы и стирание блока. Как правило, чтение всей страницы данных параллельно из плоскости во внутренний буфер занимает 10–25 мкс. Запись страницы включает в себя перемещение данных по контактам пакета и на устройство. Когда данные находятся во внутреннем буфере, запись обычно занимает от 200 мкс (SLC) до 800 мкс (MLC).Запись может изменить только все биты на странице с 1 на 0. Следовательно, запись реализуется путем выборочного изменения битов с 1 на 0 для соответствия предоставленному содержимому, предполагая, что все биты на целевой странице перед записью равны 1. Единственный способ изменить бит на странице с 0 на 1 — это стереть блок, содержащий страницу. Таким образом, удаление требуется для произвольного изменения содержимого страницы [9]. Erase устанавливает все биты в блоке на 1. Обычно стирание всего блока занимает 1,5–2 мс.В таблице 3 приведена производительность чтения, записи и стирания пяти микросхем флэш-памяти, выпущенных четырьмя производителями. Grupp et al. [35] утверждали, что показатели производительности предоставляются производителями. Они провели всестороннюю оценку с использованием устройств флэш-памяти от пяти производителей и сообщили об очень интересных наблюдениях. Согласно Таблице 3, время программы флэш-памяти одинаково для всех страниц. Однако Grupp et al. наблюдали значительное изменение времени выполнения программы в каждом блоке MLC.Все измеренные ими устройства MLC продемонстрировали регулярное и предсказуемое изменение задержки программы между страницами в блоке. Например, для одного флэш-устройства, которое они использовали, первые четыре страницы и каждая вторая пара страниц в каждом блоке в среднем в 5,8 раз быстрее, чем другие страницы. Они подытожили, что быстрые программы MLC почти так же быстры, как программы SLC, в то время как медленные страницы действительно очень медленные.
Доступ к флэш-памяти обычно состоит из фазы настройки и фазы занятости.Например, первая фаза записи предназначена для установки команд и передачи данных. Команда, адрес данных и данные записываются в соответствующие регистры флэш-памяти по порядку. Вторая фаза — это ожидание, когда данные будут сброшены во флэш-память. Чтение аналогично чтению, за исключением того, что переключается последовательность передачи данных и ожидания-занятости. Этапы стирания такие же, как и при записи, за исключением того, что на этапе настройки нет передачи данных. Последовательность операций чтения, записи и стирания показана на рис.4 [11].
Рис. 4. Последовательность операций чтения, записи и стирания.
Страница не найдена
Моя библиотека
раз- Моя библиотека
Hitex: Уровни трансляции флэш-памяти
Для эффективного использования устройств флэш-памяти NAND и NOR во встроенных системах требуется надлежащее управление флэш-памятью.Надежный уровень перевода SafeFTL Flash обеспечивает высокопроизводительное решение, которое позволяет разработчикам взаимодействовать с любым носителем на основе флэш-памяти. SafeFTL представляет собой простой логический секторный интерфейс для приложения, такого как файловая система, и эффективно и безопасно управляет лежащей в основе сложностью. В сочетании с профессиональными файловыми системами есть полное решение практически для любого типа носителя и требований к производительности.
Технологии управления флэш-памятью
- Улучшенное выравнивание износа
Из-за своей технической природы флэш-ячейки имеют ограниченный срок службы и могут быть очищены и запрограммированы только определенное количество раз, прежде чем они станут ненадежными, т.е.е. они «изнашиваются». Алгоритмы выравнивания износа используются для максимального продления срока службы микросхемы путем перемещения данных между физическими блоками, чтобы гарантировать, что одни ячейки не используются чрезмерно по сравнению с другими. Реализованные алгоритмы можно настроить в соответствии с требованиями к производительности. - Коды коррекции ошибок (ECC)
Производители флэш-памяти определяют наихудший уровень износа. Коды исправления ошибок используются для обеспечения согласованности данных, если они используются в спецификации микросхемы. Сила требуемого кода коррекции ошибок определяется интенсивностью отказов битов в наихудшем случае. - Управление ошибочными блоками
Флэш-память содержит блоки, которые могут быть дефектными на новом устройстве. Также во время работы данные в «хороших блоках» могут быть повреждены утечкой заряда или помехами из-за записи в соседних частях микросхемы. SafeFTL обеспечивает управление сбойными блоками и отображает неиспользуемые области, чтобы гарантировать, что данные не повреждены. - Ошибки нарушения чтения
Ошибки нарушения чтения возникают, когда операция чтения на одной странице вызывает изменение одного или нескольких битов на других страницах того же блока.Выполнение множества операций чтения на страницах внутри блока без промежуточного стирания этого блока увеличивает риск развития битовых ошибок. SafeFTL включает стратегии, которые легко справляются с этой проблемой. - Отказоустойчивость
Обычные файловые системы не являются отказоустойчивыми и часто испытывают трудности при возникновении общих проблем, таких как потеря питания или неожиданный сброс. Использование SafeFTL в правильно спроектированной системе гарантирует, что данные всегда будут согласованными. Чтобы обеспечить максимальную целостность, базовые драйверы носителей также предназначены для обеспечения отказоустойчивого поведения.
Подробнее см. FTL Overview.pdf
Audio Translation Layer — Lumberyard User Guide
Уровень трансляции аудио (ATL) управляет состоянием аудиосистемы и реле. запросы игры к нижележащему промежуточному программному обеспечению аудио. ATL — это общий уровень, который не содержит код, специфичный для промежуточного программного обеспечения, который позволяет использовать различное промежуточное программное обеспечение для обработки звука. реализации.ATL управляет аудиообъектами и их состояниями, а также любыми загруженными аудиофайлы, такие как звуковые банки.
Редактор управления звуком
The Audio Controls Editor (ACE) — это плагин Lumberyard Editor, который управляет сопоставлениями между ATL на стороне игры. элементы управления и их эквиваленты промежуточного программного обеспечения для аудио.
Элементы управления ATL поддерживают гибкий рабочий процесс для проекта, например следующие случаи:
Вы готовы интегрировать звуки в свою игру, но контент промежуточного аудио еще не создано.Вы можете сначала создать элементы управления ATL и интегрировать их в игра. Когда аудиоконтент завершен, вы можете подключить существующие элементы управления ATL к новому элементы управления промежуточного программного обеспечения.
Позже вы вносите изменения в свой проект в элементы управления промежуточного программного обеспечения, что нарушает подключения к их элементам управления ATL.Вместо того, чтобы находить каждый экземпляр, в котором вы использовали звук, вы можете исправить связь между ATL и промежуточным программным обеспечением. Это автоматически исправляет сломанные соединения.
D3D12 Translation Layer и D3D11On12 теперь имеют открытый исходный код
Анджела Цзян
Если вы разработчик и хотите перенести свою игру на DX12, у нас есть хорошие новости: есть вспомогательная библиотека, которая упростит вам задачу!
Мы рады сообщить, что уровень перевода D3D12 теперь имеет открытый исходный код.Уровень перевода D3D12 — это вспомогательная библиотека для перевода концепций и команд графики из домена в стиле D3D11 в домен в стиле D3D12. В качестве примера использования библиотеки мы также открыли исходный код D3D11On12, слой сопоставления, который отображает графические команды из D3D11 в D3D12.
Проверьте исходный код на GitHub:
Прочтите, чтобы узнать больше о том, что это значит для вас.
Немного истории: зачем наносить на карту слои?
Первый проект картографического слоя был начат во время разработки Windows 10 и D3D12.У графической команды Windows есть большой набор контента D3D11, который активно использовался во время разработки и внедрения моделей среды выполнения и драйверов D3D12. Чтобы использовать это содержимое, был разработан слой сопоставления с именем D3D11On12.
Этот слой отображения оказался успешным и полезным до такой степени, что был разработан второй слой отображения, названный D3D9On12. Как следует из названия, он преобразуется из D3D9 в D3D12 и должен решать множество тех же проблем, что и D3D11On12. Таким образом, D3D11On12 был реорганизован на две части: часть, которая реализует концепции, специфичные для D3D11, и более общая часть, которая переводит более традиционные графические конструкции в современного низкоуровневого потребителя D3D12 API.Эта более общая часть и стала уровнем перевода D3D12. Код уровня перевода в настоящее время используется двумя уровнями сопоставления, которые поставляются как часть Windows: D3D11On12 и D3D9On12.
Мы понимаем, что уровень перевода D3D12 решает проблемы, которые не уникальны для 11On12 и 9On12, и мы делимся исходным кодом с сообществом разработчиков графики, чтобы другие могли повторно использовать и получать выгоду от нашей работы. И уровень перевода D3D12, и D3D11On12 доступны на GitHub сегодня. Если у вас возникнут вопросы, пока вы играете с кодом, не стесняйтесь обращаться к нам в Discord.
Что можно делать с кодом?
- Более быстрый переход на D3D12. Используйте библиотеку слоев перевода D3D12 как есть в своей игре, чтобы быстрее перенести существующую работу в D3D12.
- Создайте слой сопоставления из любимого графического или вычислительного API в D3D12. Воспользуйтесь преимуществами протестированного и совместимого драйвера IHV DirectX 12 с помощью собственной оболочки D3D12.
- Снова внесите свой вклад в Windows. Мы приветствуем вклад сообщества как в уровень перевода D3D12, так и в D3D11On12.Улучшения будут возвращены в кодовую базу Windows и, в конечном итоге, появятся в будущих версиях Windows 10.
Узнать больше
Кодированиедля твердотельных накопителей — Часть 3: страницы, блоки и уровень трансляции Flash
Это часть 3 по 6 «Кодирования для твердотельных накопителей», охватывающая разделы 3 и 4. Для других частей и разделов вы можете обратиться к таблице к содержанию. Это серия статей, которые я написал, чтобы поделиться тем, что я узнал, документируя себя на SSD, а также о том, как заставить код работать на SSD.Если вы спешите, вы также можете сразу перейти к Части 6, в которой суммируется содержание всех остальных частей.
В этой части я объясняю, как записи обрабатываются на уровне страницы и блока, и говорю о фундаментальных концепциях усиления записи и выравнивания износа. Более того, я описываю, что такое Flash Translation Layer (FTL), и рассматриваю две его основные цели: отображение логических блоков и сборку мусора. В частности, я объясняю, как работают операции записи в контексте гибридного отображения блоков журнала.
Переводы : Эта статья была переведена на упрощенный китайский компанией Xiong Duo и на корейский язык — Мэттом Ли (이 성욱).
3. Основные операции
3.1 Чтение, запись, стирание
Из-за организации ячеек NAND-flash невозможно читать или записывать отдельные ячейки по отдельности. Память сгруппирована и доступна с очень специфическими свойствами. Знание этих свойств имеет решающее значение для оптимизации структур данных для твердотельных накопителей и понимания их поведения.Ниже я описываю основные свойства твердотельных накопителей, касающиеся операций чтения, записи и стирания.
Чтения выровнены по размеру страницы
Невозможно прочитать меньше одной страницы за один раз. Конечно, можно запросить только один байт из операционной системы, но полная страница будет извлечена на SSD, в результате чего будет прочитано гораздо больше данных, чем необходимо.
Записи выровнены по размеру страницы
При записи на SSD запись происходит с увеличением размера страницы.Таким образом, даже если операция записи затрагивает только один байт, все равно будет записана вся страница. Запись большего количества данных, чем необходимо, называется усилением записи, концепция, описанная в разделе 3.3. Кроме того, запись данных на страницу иногда называют «программированием» страницы, поэтому термины «запись» и «программа» взаимозаменяемы в большинстве публикаций и статей, связанных с твердотельными накопителями.
Страницы не могут быть перезаписаны
Страница NAND-flash может быть записана, только если она находится в «свободном» состоянии.При изменении данных содержимое страницы копируется во внутренний регистр, данные обновляются, и новая версия сохраняется на «свободной» странице, операция называется «чтение-изменение-запись». Данные не обновляются на месте, так как «бесплатная» страница отличается от страницы, которая изначально содержала данные. После того, как данные сохраняются на диске, исходная страница помечается как «устаревшая» и остается такой до тех пор, пока не будет удалена.
Стирание выравнивается по размеру блока
Страницы не могут быть перезаписаны, и как только они станут устаревшими, единственный способ освободить их снова — это стереть их.Однако невозможно стереть отдельные страницы, а можно стереть только целые блоки сразу. С точки зрения пользователя, при доступе к данным могут выдаваться только команды чтения и записи. Команда стирания запускается автоматически процессом сборки мусора в контроллере SSD, когда ему необходимо восстановить устаревшие страницы, чтобы освободить место.
3.2 Пример записи
Проиллюстрируем концепции из раздела 3.1. На рисунке 4 ниже показан пример записи данных на SSD.Показаны только два блока, и каждый из этих блоков содержит только четыре страницы. Это, очевидно, упрощенное представление пакета NAND-flash, созданное для приведенных здесь сокращенных примеров. На каждом этапе рисунка маркеры справа от схемы объясняют, что происходит.
Рисунок 4: Запись данных на твердотельный накопитель
3.3 Усиление записи
Поскольку записи выравниваются по размеру страницы, любая операция записи, которая не выровнена одновременно по размеру страницы и кратному размеру страницы, потребует записи большего количества данных, чем необходимо, концепция, называемая усилением записи [13].Запись одного байта приведет к написанию страницы, которая может составлять до 16 КБ для некоторых моделей SSD и быть крайне неэффективной.
Но это не единственная проблема. Помимо записи большего количества данных, чем необходимо, эти записи также вызывают больше внутренних операций, чем необходимо. Действительно, запись данных невыровненным способом приводит к тому, что страницы считываются в кэш перед изменением и записью обратно на диск, что медленнее, чем прямая запись страниц на диск. Эта операция известна как чтение-изменение-запись , и ее следует по возможности избегать [2, 5].
Никогда не пишите меньше страницы
Избегайте записи фрагментов данных, размер которых меньше размера страницы NAND-flash, чтобы минимизировать усиление записи и предотвратить операции чтения-изменения-записи. Наибольший размер страницы на данный момент составляет 16 КБ, поэтому это значение следует использовать по умолчанию. Этот размер зависит от модели SSD, и вам может потребоваться увеличить его в будущем по мере совершенствования SSD.
Выровнять записи
Выровнять записи по размеру страницы и записать фрагменты данных, кратные размеру страницы.
Буфер малых записей
Чтобы максимизировать пропускную способность, по возможности сохраняйте небольшие записи в буфере ОЗУ, а когда буфер заполнен, выполняйте одну большую запись, чтобы пакетировать все мелкие записи.
3.4 Выравнивание износа
Как обсуждалось в разделе 1.1, ячейки NAND-flash имеют ограниченный срок службы из-за ограниченного количества циклов P / E. Представим, что у нас есть гипотетический SSD, в котором данные всегда считываются и записываются из одного и того же блока.Этот блок быстро превысит свой предел цикла P / E, изнашивается, и контроллер SSD отмечает его как непригодный для использования. Тогда общая емкость диска уменьшится. Представьте, что вы купили диск на 500 ГБ, а пару лет спустя остались с 250 ГБ, это было бы возмутительно!
По этой причине одной из основных целей контроллера SSD является реализация выравнивания износа , которая распределяет циклы P / E как можно более равномерно между блоками. В идеале, все блоки должны достичь пределов цикла P / E и изнашиваться одновременно [12, 14].
Для достижения наилучшего общего выравнивания износа контроллеру SSD необходимо будет разумно выбирать блоки при записи и, возможно, придется перемещать некоторые блоки, что само по себе приводит к увеличению усиления записи. Следовательно, управление блоками — это компромисс между максимальным выравниванием износа и минимизацией усиления записи.
Производители придумали различные функции для выравнивания износа, такие как сбор мусора, который рассматривается в следующем разделе.
Выравнивание износа
Поскольку ячейки NAND-flash изнашиваются, одна из основных целей FTL — как можно более равномерно распределить работу между ячейками, чтобы блоки достигли своего предела цикла P / E и изнашивались одновременно.
4. Уровень трансляции флэш-памяти (FTL)
4.1 О необходимости иметь FTL
Основным фактором, упростившим внедрение твердотельных накопителей, является то, что они используют те же главные интерфейсы, что и жесткие диски. Хотя представление массива адресов логических блоков (LBA) имеет смысл для жестких дисков, поскольку их сектора могут быть перезаписаны, это не полностью соответствует принципу работы флэш-памяти.По этой причине требуется дополнительный компонент, чтобы скрыть внутренние характеристики флэш-памяти NAND и предоставить хосту только массив LBA. Этот компонент называется Flash Translation Layer (FTL) и находится в контроллере SSD. FTL важен и имеет две основные цели: отображение логических блоков и сборка мусора.
4.2 Отображение логических блоков
Отображение логических блоков преобразует адреса логических блоков (LBA) из пространства хоста в адреса физических блоков (PBA) в пространстве физической флэш-памяти NAND.Это отображение принимает форму таблицы, которая для любого LBA дает соответствующую PBA. Эта таблица сопоставления хранится в ОЗУ твердотельного накопителя для обеспечения скорости доступа и сохраняется во флэш-памяти в случае сбоя питания. Когда SSD включается, таблица считывается из сохраненной версии и реконструируется в RAM SSD [1, 5].
Наивный подход состоит в том, чтобы использовать отображение уровня страницы для отображения любой логической страницы с хоста на физическую страницу. Эта политика сопоставления предлагает большую гибкость, но основным недостатком является то, что для таблицы сопоставления требуется много оперативной памяти, что может значительно увеличить производственные затраты.Решением этого может быть отображение блоков вместо страниц с использованием отображения на уровне блоков . Предположим, что у SSD-диска 256 страниц на блок. Это означает, что отображение на уровне блоков требует в 256 раз меньше памяти, чем отображение на уровне страниц, что является огромным улучшением для использования пространства. Однако сопоставление по-прежнему необходимо сохранить на диске в случае сбоя питания, а в случае рабочих нагрузок с большим количеством небольших обновлений будут записаны полные блоки флэш-памяти, тогда как страниц было бы достаточно.Это увеличивает усиление записи и делает отображение на уровне блоков неэффективным [1, 2].
Компромисс между отображением на уровне страниц и отображением на уровне блоков заключается в соотношении производительности и объема. Некоторые исследователи попытались получить лучшее из обоих миров, породив так называемый подход « гибрид » [10]. Наиболее распространенным является отображение блока журнала , в котором используется подход, аналогичный файловым системам с журнальной структурой. Входящие операции записи последовательно записываются в блоки журнала.Когда блок журнала заполнен, он объединяется с блоком данных, связанным с тем же номером логического блока (LBN), в свободный блок. Необходимо поддерживать только несколько блоков журнала, что позволяет поддерживать их с разбивкой по страницам. Блоки данных, напротив, поддерживаются с блочной детализацией [9, 10].
На рисунке 5 ниже показано упрощенное представление гибридного лог-блока FTL, в котором каждый блок имеет только четыре страницы. FTL обрабатывает четыре операции записи, каждая из которых имеет размер полной страницы.Оба логических номера страниц 5 и 9 разрешаются в LBN = 1, который связан с физическим блоком № 1000. Первоначально все смещения физических страниц равны нулю в записи, где LBN = 1 находится в таблице отображения блока журнала , и блок журнала # 1000 также полностью пуст. Первая запись, b ’при LPN = 5, разрешается в LBN = 1 таблицей отображения блока журнала, которая связана с PBN = 1000 (блок журнала # 1000). Таким образом, страница b ’записывается с физическим смещением 0 в блоке # 1000. Теперь необходимо обновить метаданные для сопоставления, и для этого физическое смещение, связанное с логическим смещением 1 (произвольное значение для этого примера), обновляется с нуля до 0.
Операции записи продолжаются, и метаданные отображения обновляются соответствующим образом. Когда блок журнала №1000 полностью заполнен, он объединяется с блоком данных, связанным с тем же логическим блоком, которым в данном случае является блок №3000. Эта информация может быть извлечена из таблицы отображения блоков данных , которая отображает номера логических блоков на номера физических блоков. Данные, полученные в результате операции слияния, записываются в свободный блок, в данном случае # 9000. Когда это будет сделано, оба блока №1000 и №3000 могут быть стерты и станут свободными блоками, а блок №9000 станет блоком данных.Метаданные для LBN = 1 в таблице отображения блоков данных затем обновляются с начального блока данных № 3000 до нового блока данных № 9000.
Здесь важно отметить, что четыре операции записи были сосредоточены только на двух LPN. Подход с блокировкой журнала позволил скрыть операции b ’и d’ во время слияния и напрямую использовать более современные версии b ”и d”, что позволяет добиться лучшего усиления записи.
Наконец, если команда чтения запрашивает страницу, которая была недавно обновлена и для которой шаг слияния блоков еще не произошел, тогда страница будет в блоке журнала.В противном случае на странице будет обнаружен блок данных. Вот почему запросы на чтение должны проверять как таблицу сопоставления блоков журнала , так и таблицу сопоставления блоков данных , как показано на рисунке 5.
Рисунок 5: Гибридный лог-блок FTL
FTL блока журнала допускает оптимизацию, наиболее заметной из которых является переключение-слияние , иногда называемое «слияние-своп». Представим, что все адреса в логическом блоке были записаны сразу. Это будет означать, что все новые данные для этих адресов будут записаны в один и тот же блок журнала.Поскольку этот блок журнала содержит данные для всего логического блока, было бы бесполезно объединять этот блок журнала с блоком данных в свободный блок, потому что результирующий свободный блок будет содержать именно те данные, что и блок журнала. Было бы быстрее обновлять только метаданные в таблице сопоставления блоков данных и переключать блок данных в таблице сопоставления блоков данных для блока журнала, это переключение-слияние.
Схема отображения лог-блоков была темой многих статей, что привело к ряду улучшений, таких как FAST (полностью ассоциативное преобразование секторов), отображение суперблоков и гибкое групповое отображение [10].Существуют также другие схемы отображения, такие как алгоритм Мицубиси и SSR [9]. Двумя отличными отправными точками для получения дополнительных сведений о FTL и схемах картографии являются два следующих документа:
- « Обзор уровня флэш-трансляции », Чанг и др., 2009 г. [9]
- « Реконфигурируемая архитектура FTL (уровень флэш-трансляции) для приложений на базе флэш-памяти NAND », Парк и др., 2008 г. [10]
Уровень перевода Flash
Уровень трансляции флэш-памяти (FTL) — это компонент контроллера SSD, который сопоставляет адреса логических блоков (LBA) хоста с адресами физических блоков (PBA) на накопителе.В самых последних накопителях реализован подход, называемый «гибридное отображение блоков журнала» или один из его производных, который работает аналогично файловым системам с журнальной структурой. Это позволяет обрабатывать случайные записи как последовательные.
4.3 Примечания о состоянии отрасли
По состоянию на 2 февраля 2014 г. в Википедии перечислено 70 производителей твердотельных накопителей [64], и, что интересно, всего 11 производителей контроллеров [65]. Из 11 производителей контроллеров только четыре являются «зависимыми», т.е.е. они используют свои контроллеры только для собственных продуктов (это случай Intel и Samsung), а остальные семь являются «независимыми», т.е. продают свои контроллеры другим производителям накопителей. Эти цифры говорят о том, что семь компаний поставляют контроллеры для 90% рынка твердотельных накопителей.
У меня нет данных о том, какие производители контроллеров продают какому производителю приводов из этих 90%, но, следуя принципу Парето, я готов поспорить, что только два или три производителя контроллеров делят большую часть пирога.Прямым следствием является то, что твердотельные накопители от производителей, не являющихся независимыми, с большой вероятностью будут вести себя аналогичным образом, поскольку они, по сути, работают с одними и теми же контроллерами или, по крайней мере, контроллерами, использующими один и тот же общий дизайн и основные идеи.
Схемы сопоставления, которые являются частью контроллера, являются критически важными компонентами твердотельных накопителей, поскольку они часто полностью определяют производительность диска. Это объясняет, почему в отрасли с такой большой конкуренцией производители контроллеров SSD не раскрывают детали своих реализаций FTL.Поэтому, несмотря на то, что существует множество общедоступных исследований алгоритма FTL, всегда неясно, какая часть этих исследований используется производителями контроллеров и каковы точные реализации для конкретных брендов и моделей.
Авторы [3] утверждают, что, анализируя рабочие нагрузки, они могут реконструировать политики отображения диска. Я бы сказал, что если только сам двоичный код не реверсируется из чипа, нет никакого способа быть полностью уверенным в том, что политика сопоставления действительно делает внутри конкретного диска.И еще сложнее предсказать, как отображение будет вести себя при определенной рабочей нагрузке.
Существует множество различных политик сопоставления, и на обратное проектирование всех доступных встроенных программ потребуется много времени. Тогда, даже после получения исходного кода всех возможных политик сопоставления, какая будет польза? Системные требования новых проектов часто заключаются в том, чтобы дать хорошие общие результаты при использовании универсального и взаимозаменяемого серийного оборудования.Следовательно, было бы бесполезно оптимизировать только одну политику сопоставления, потому что решение, вероятно, будет плохо работать со всеми другими политиками сопоставления. Единственная причина, по которой нужно оптимизировать только для одного типа политики, — это разработка для встроенной системы, которая гарантированно будет иметь согласованное оборудование.
По причинам, указанным выше, я бы сказал, что знание точной политики сопоставления SSD не имеет значения. Единственное, что нужно знать, — это то, что схемы сопоставления — это уровень трансляции между LBA и PBA, и весьма вероятно, что используемый подход — это гибридный лог-блок или одна из его производных.Следовательно, запись фрагментов данных размером, по крайней мере, размером с блок NAND-flash более эффективна, потому что для FTL она минимизирует накладные расходы на обновление отображения и его метаданных.
4.4 Сборка мусора
Как объяснено в разделах 4.1 и 4.2, страницы не могут быть перезаписаны. Если данные на странице необходимо обновить, новая версия записывается на бесплатную страницу , а страница, содержащая предыдущую версию, помечается как устаревшая . Если блоки содержат устаревшие страницы, их необходимо стереть, прежде чем на них можно будет выполнить запись.
Сборка мусора
Процесс сборки мусора в контроллере SSD гарантирует, что «устаревшие» страницы будут удалены и восстановлены в «свободное» состояние, чтобы можно было обрабатывать входящие команды записи.
Из-за большой задержки, требуемой для команды стирания по сравнению с командой записи, которая составляет соответственно 1500-3500 мкс и 250-1500 мкс, как описано в разделе 1, этот дополнительный этап стирания вызывает задержку, которая замедляет запись. Таким образом, некоторые контроллеры реализуют процесс фоновой сборки мусора , также называемый незанятой сборкой мусора , который использует время простоя и регулярно запускается в фоновом режиме, чтобы освободить устаревшие страницы и гарантировать, что будущие операции переднего плана будут иметь достаточно свободных страниц, доступных для достичь максимальной производительности [1].В других реализациях используется подход параллельной сборки мусора , который выполняет операции сборки мусора параллельно с операциями записи с хоста [13].
Нередко встречаются рабочие нагрузки, в которых операции записи настолько велики, что сборку мусора необходимо запускать «на лету» одновременно с командами с хоста. В этом случае процесс сборки мусора, который должен выполняться в фоновом режиме, мог мешать командам переднего плана [1].Команда TRIM и избыточное выделение ресурсов — два отличных способа уменьшить этот эффект, которые более подробно рассматриваются в разделах 6.1 и 6.2.
Фоновые операции могут влиять на операции переднего плана
Фоновые операции, такие как сборка мусора, могут негативно повлиять на операции переднего плана с хоста, особенно в случае постоянной рабочей нагрузки небольших случайных записей.
Менее важной причиной перемещения блоков является нарушение чтения .Чтение может изменить состояние соседних ячеек, поэтому блоки необходимо перемещать после того, как будет выполнено определенное количество чтений [14].
Скорость изменения данных является важным фактором. Некоторые данные меняются редко и называются холодными или статическими данными , в то время как некоторые другие данные обновляются часто, что называется горячими или динамическими данными . Если на странице хранятся частично холодные и частично горячие данные, то холодные данные будут скопированы вместе с горячими данными во время сборки мусора для выравнивания износа, увеличивая усиление записи из-за наличия холодных данных.Этого можно избежать, отделив холодные данные от горячих, просто сохранив их на отдельных страницах. Таким образом, недостатком является то, что страницы, содержащие холодные данные, стираются реже, и поэтому блоки, хранящие холодные и горячие данные, необходимо регулярно менять местами для обеспечения выравнивания износа.
Так как «горячая» информация определяется на уровне приложения, FTL не имеет возможности узнать, сколько «холодных» и «горячих» данных содержится на одной странице. Способ повышения производительности SSD — это максимально возможное разделение горячих и холодных данных на отдельные страницы, что упростит работу сборщика мусора [8].
Разделение холодных и горячих данных
Горячие данные — это данные, которые часто меняются, а холодные данные — это данные, которые меняются нечасто. Если некоторые горячие данные хранятся на той же странице, что и некоторые холодные данные, холодные данные будут копироваться каждый раз, когда горячие данные обновляются в операции чтения-изменения-записи, и будут перемещаться во время сборки мусора для выравнивания износа. Максимальное разделение горячих и холодных данных на отдельные страницы облегчит работу сборщика мусора.
Буфер горячих данных
Чрезвычайно горячие данные следует как можно больше буферизовать и как можно реже записывать на диск.
Сделать недействительными устаревшие данные большими партиями
Когда некоторые данные больше не нужны или их нужно удалить, лучше подождать и аннулировать их большими партиями за одну операцию. Это позволит процессу сборщика мусора одновременно обрабатывать большие области и поможет минимизировать внутреннюю фрагментацию.
Что дальше?
Часть 4 доступна здесь. Вы также можете перейти к оглавлению для этой серии статей, а если вы спешите, вы также можете сразу перейти к части 6, в которой суммируется контент из всех других частей.
Список литературы
[1] Понимание внутренних характеристик и системных значений твердотельных накопителей на основе флэш-памяти, Чен и др., 2009 г.
[2] Параметрическое управление вводом-выводом для твердотельных дисков (SSD), Ким и др., 2012
[3] Важнейшие роли использования внутреннего параллелизма твердотельных накопителей на основе флэш-памяти в высокоскоростной обработке данных, Чен и др., 2011
[4] Изучение и использование многоуровневого параллелизма внутри твердотельных накопителей для повышения производительности и долговечности, Ху и др., 2013 г.
[5] Компромисс дизайна для производительности SSD, Агравал и др., 2008 г.
[6] Шаблоны проектирования для настраиваемых и эффективных индексов на основе SSD, Ананд и др., 2012 г.
[7] BPLRU: буфер Схема управления для улучшения случайных записей во флэш-памяти, Ким и др., 2008
[8] SFS: Случайная запись считается вредной для твердотельных накопителей, Мин и др., 2012 г.
[9] Обзор уровня трансляции флэш-памяти, Чанг и др., 2009 г.
[10] Реконфигурируемый FTL (флэш-перевод Layer) Архитектура для приложений на основе флэш-памяти NAND, Парк и др., 2008 г.
[11] Надежное стирание данных с твердотельных накопителей на основе флэш-памяти, Вэй и др., 2011 г.
[12] http://en.wikipedia.org / wiki / Solid-state_drive
[13] http://en.wikipedia.org/wiki/Write_amplification
[14] http: // en.wikipedia.org/wiki/Flash_memory
[15] http://en.wikipedia.org/wiki/Serial_ATA
[16] http://en.wikipedia.org/wiki/Trim_(computing)
[17] http: //en.wikipedia.org/wiki/IOPS
[18] http://en.wikipedia.org/wiki/Hard_disk_drive
[19] http://en.wikipedia.org/wiki/Hard_disk_drive_performance_characteristics
[20] http : //centon.com/flash-products/chiptype
[21] http://www.thessdreview.com/our-reviews/samsung-64gb-mlc-ssd/
[22] http: //www.anandtech. com / show / 7594 / samsung-ssd-840-evo-msata-120gb-250gb-500gb-1tb-review
[23] http: // www.anandtech.com/show/6337/samsung-ssd-840-250gb-review/2
[24] http://www.storagereview.com/ssd_vs_hdd
[25] http://www.storagereview.com/wd_black_4tb_desktop_hard_drive_freview_wd40070 [26] http://www.storagereview.com/samsung_ssd_840_pro_review
[27] http://www.storagereview.com/micron_p420m_enterprise_pcie_ssd_review
[28] http://www.storagereview.com/intel_x25-m_ssd_review
[27] http://www.storagereview.com/seagate_momentus_xt_750gb_review
[30] http: // www.storagereview.com/corsair_vengeance_ddr3_ram_disk_review
[31] http://arstechnica.com/information-technology/2012/06/inside-the-ssd-revolution-how-solid-state-disks-really-work/
[32] http : //www.anandtech.com/show/2738
[33] http://www.anandtech.com/show/2829
[34] http://www.anandtech.com/show/6489
[35] http://lwn.net/Articles/353411/
[36] http://us.hardware.info/reviews/4178/10/hardwareinfo-tests-lifespan-of-samsung-ssd-840-250gb-tlc- ssd-updated-with-final-closed-final-update-20-6-2013
[37] http: // www.anandtech.com/show/6489/playing-with-op
[38] http://www.ssdperformanceblog.com/2011/06/intel-320-ssd-random-write-performance/
[39] http: / /en.wikipedia.org/wiki/Native_Command_Queuing
[40] http://superuser.com/questions/228657/which-linux-filesystem-works-best-with-ssd/
[41] http: // blog. superuser.com/2011/05/10/maximizing-the-lifetime-of-your-ssd/
[42] http://serverfault.com/questions/356534/ssd-erase-block-size-lvm-pv- on-raw-device-alignment
[43] http: // rethinkdb.com / blog / page-alignment-on-ssds /
[44] http://rethinkdb.com/blog/more-on-alignment-ext2-and-partitioning-on-ssds/
[45] http: // rickardnobel.se/storage-performance-iops-latency-throughput/
[46] http://www.brentozar.com/archive/2013/09/iops-are-a-scam/
[47] http: // www.acunu.com/2/post/2011/08/why-theory-fails-for-ssds.html
[48] http://security.stackexchange.com/questions/12503/can-wiped-ssd-data -be-recovery
[49] http://security.stackexchange.com/questions/5662/is-it-enough-to-only-wipe-a-flash-drive-once
[50] http: // searchsolidstatestorage .techtarget.com/feature/The-truth-about-SSD-performance-benchmarks
[51] http://www.theregister.co.uk/2012/12/03/macronix_thermal_annealing_extends_life_of_flash_memory/
[52] http: // www .eecs.berkeley.edu / ~ rcs / research / interactive_latency.html
[53] http://blog.nuclex-games.com/2009/12/aligning-an-ssd-on-linux/
[54] http : //www.linux-mag.com/id/8397/
[55] http://tytso.livejournal.com/2009/02/20/
[56] https://wiki.debian.org/SSDOptimization
[57] http: //wiki.gentoo.org / wiki / SSD
[58] https://wiki.archlinux.org/index.php/Solid_State_Drives
[59] https://www.kernel.org/doc/Documentation/block/cfq-iosched.txt
[60] http://www.danielscottlawrence.com/blog/should_i_change_my_disk_scheduler_to_use_NOOP.html
[61] http://www.phoronix.com/scan.php?page=article&item=linux_iosched_2012
[62] http: // www .velobit.com / storage-performance-blog / bid / 126135 / Effects-Of-Linux-IO-Scheduler-On-SSD-Performance
[63] http://www.axpad.com/blog/301
[64 ] http: // en.wikipedia.org/wiki/List_of_solid-state_drive_manufacturers
[65] http://en.wikipedia.org/wiki/List_of_flash_memory_controller_manufacturers
[66] http://blog.zorinaq.com/?e=29
[67] http: //www.gamersnexus.net/guides/956-how-ssds-are-made
[68] http://www.gamersnexus.net/guides/1148-how-ram-and-ssds-are-made-smt -lines
[69] http://www.tweaktown.com/articles/4655/kingston_factory_tour_making_of_an_ssd_from_start_to_finish/index.html
[70] http://www.youtube.com/watch?v=DvA9koAMXR8
[71] http: // www.youtube.com/watch?v=3s7KG6QwUeQ
[72] Понимание устойчивости твердотельных накопителей при сбое питания, Чжэн и др., 2013 г. — [обсуждение HN]
[73] http://lkcl.net/reports/ssd_analysis. html — [обсуждение HN]
Обеспечение уровня надежности флеш-трансляции (RA): оптимизированная стратегия для выравнивания износа и сборки мусора
Выбрать коллекцию Все коллекции SDSU Тезисы и диссертации SDSU Фотоальбом Энни Л. Джобс, 1884-1887 годы Записки Артуро Касарес Дневники Аса СакманАссоциированные студентыАвенская государственная тюрьмаАцтекские выпускники НовостиЧерные рукописи Донны БаррBrightSide ProduceКоллекция кнопок и значковКалифорнийский институт реабилитации женщин Калифорнии Калифорнийский институт помощи для женщин Калифорния ГрафствоКалипатрия Государственная тюрьма Коллекция плакатов Кармен Сандовал ФернандесЦентр региональной устойчивости (CRS) Сообщество чикана и чиканоМежрасовый комитет гражданГород Ла-МесаГород Лимонная рощаГород национального городаГород Сан-ДиегоГород СантиГород ТихуанаКомикшн. Альбом Мура: Гордость 1982 года и не только ЛекцияGay Liberation FrontОбщие каталогиГеологические науки Старшие тезисы выпускников Бюллетени для выпускниковИсторическая эфемера Государственная тюрьма АйронвудДжон АдамсЛюбовные статьи Джона и Джейн Адамс Коллекция открыток Джона и Джейн Адамс Коллекция торговых карточек Джона и Джейн Адамс Коллекция памятных вещей семьи Джона, 1962-2002 гг. Коллекция фотографий Ван ДирлинаВыбор коллекции картМарк Фриман Коллекция фотографий Old Globe Theater Коллекция устных историй Лиги пожилых женщин (OWL) Другие голоса: Альтернативные периодические издания в Государственном университете Сан-Диего Коллекция Храма Людей (1972–1990) Фотографии прайда от Кристин Кехо, 1970–1990-е гг. Коллективные учебные программыРадикальные эфемеры и подпольные публикацииРелигиозные движенияСобрание воспоминаний о COVID-19SDSUСборник цифровых гуманитарных наукSDSU Работа преподавателей и сотрудников SDSU ksSDSU Mission ValleySDSU Research Foundation GrantsSDSU Студенческие газетыSDSU Студенческий исследовательский симпозиумSDSU Студенческие работыSDSU Syllabus Collection Каталоги курсов, бюллетени и т. д.San Diego Ballet Коллекция Black Panther в Сан-ДиегоИстория Сан-ДиегоЧертежи Нормальной школы Сан-ДиегоКоллекция фотографий Сан-Диего Pride Ephemera КоллекцияSan Diego Pride GuidesSan Diego Pride Photograph collection Экологический заповедник Маргариты Школа медсестер Шейла Кларк и Джуди Рейф в Сан-Диего Прайд Отчеты об исследованиях Инициативы по социальным и экономическим уязвимостям (SEVI) Устные рассказы студентов Письмо ацтекских новостей, 1942-1946 Центр в Прайде, 1990-е годы Проект Sage в SDSUThomas M.Статьи и лекции Дэвиса-младшего. Коллекция архивов университета. Архивы университета. Мультимедиа.
Поисковая строка
Расширенный поиск .